AI share of voice is the percentage of AI answers, across a set of prompts, where your brand gets named instead of a competitor. It is the closest thing AI search has to a ranking, and the metric every tool in the category now leads with.
It is also the easiest to game, mostly by accident. The number you get depends entirely on which prompts you test and which competitors you count, and most tools never show you either.
What Is AI Share of Voice?
AI share of voice (AI SoV) measures how much of the AI conversation in your category belongs to you. Across a fixed set of prompts, it is the share of answers that name, cite, or recommend your brand, measured against the competitors you track.
It exists because AI answers are close to zero-sum. A page of Google links has room for ten results and a stack of ads. An AI answer names a handful of brands and moves on. Either you are in that short list or you are invisible, so the useful question shifts from "where do I rank" to "how often am I the one mentioned, versus them." Getting a reliable read on that means tracking brand mentions in AI search across repeated runs, not a single check.
That makes share of voice the closest thing AI search has to a rank. It is not the same as a blended AI visibility score, which rolls mentions, citations, sentiment, and more into one number. Share of voice is the single competitive slice underneath it: your mentions as a percentage of all brand mentions. And it is not your Google ranking. You can sit at position one for a query and never appear in the AI answer to the same question. Tracking that presence over time is the job of ongoing AI visibility tracking; share of voice is the number it reports.
From Share of Voice to Share of Search to AI
Share of voice is not a new idea. Marketers have measured it for decades as a brand's slice of the category's advertising, media coverage, or conversation. The logic has always been that the brand that owns the conversation tends to own the market.
The sharpest modern version is share of search: your share of brand searches in a category. Presenting the metric at the IPA's EffWorks 2020 conference, Les Binet showed it works as a leading indicator of market share, moving months ahead of sales, up to a year in some categories. Later IPA think-tank work across thirty case studies found share of search corresponds to roughly 83% of a brand's share of market on average, a correlation rather than a causal law.
AI share of voice is the next link in that chain. Instead of your slice of ad spend or your slice of searches, it is your slice of the answers an AI gives when someone asks about your category. The instinct is identical: presence in the conversation predicts preference.
One thing that made the older metrics trustworthy is missing here, though. Share of spend and share of search have stable, external denominators: total category ad spend, total category searches. Nobody lets you redraw them. AI share of voice has no such fixed denominator. You build it yourself every time you pick a prompt set and a competitor list, which is exactly where the metric gets slippery.
How to Calculate AI Share of Voice
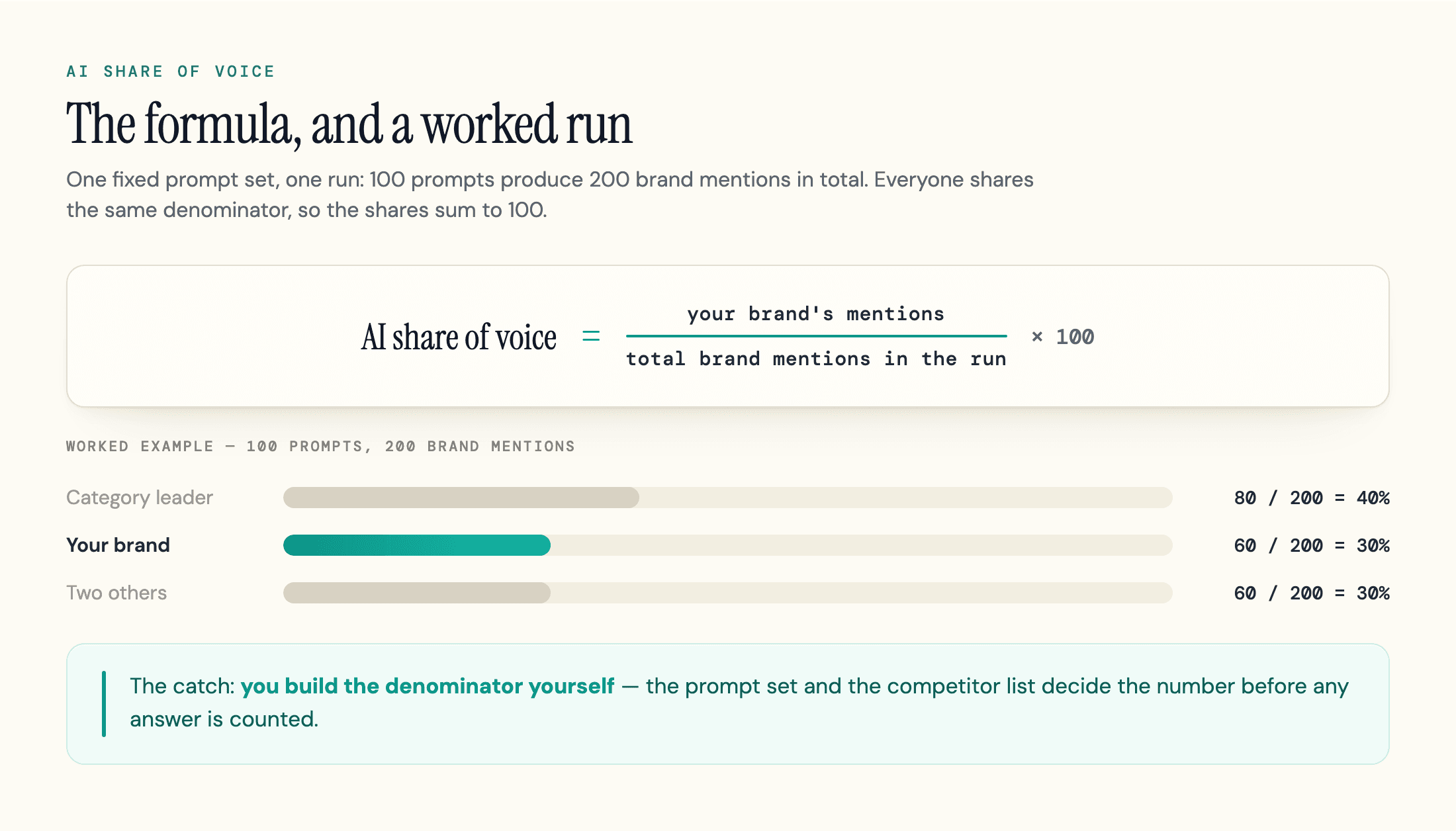
The basic formula is simple. Pick a set of prompts your buyers actually ask, run them across the AI engines you care about, and count:
AI share of voice = (your brand's mentions / total brand mentions across the run) × 100
Run 100 prompts, count every brand named across the answers, and divide your mentions by that total. If the run produces 200 brand mentions and 60 are yours, your share of voice is 30%. The same run gives you the full split: you at 30%, the category leader at 40%, two others sharing the rest, summing to 100 because everyone shares one denominator.
You will also see a simpler presence rate quoted (the percentage of answers that name you at all); useful, but those figures overlap across brands and do not sum to 100, so do not mix the two on one slide.
The catch is the word "mention." There are at least three ways to count it, and they do not agree.
Three Ways to Count, Three Different Numbers
| Method | What it counts | Tends to score |
|---|---|---|
| Mention-based | Any time your brand name appears in the answer | Middle |
| Citation-based | Only when the answer links or attributes a claim to your site | Lowest |
| Position-weighted | Mentions weighted by placement (named first counts more than tenth) | Highest if you lead |
Run the same prompt set three ways and identical data can produce very different numbers: a brand near 30% on raw mentions might read closer to 17% on citations and 31% when weighted by position. None is wrong. They answer different questions. Mention-based asks "am I in the conversation," citation-based asks "am I a source," position-weighted asks "am I the recommendation."
The mistake is comparing one tool's mention-based score against another's citation-based score and concluding something changed. Pick one definition, write it down, and hold it. The number only means something against itself.
The Denominator Problem
Here is the part most share-of-voice tools would rather you not think about. You choose the denominator.
In an old rank tracker, your denominator was fixed and public: you defined a keyword list, and that list was the universe you were measured against. Anyone could look at it and argue with it. AI share of voice quietly hands you control of both halves of the fraction. You pick the prompts (the questions that get asked) and you pick the competitor set (the brands that get counted). Change either and your share moves without anything changing in the market.
Stack the prompt set with questions you already win and your number climbs. Leave a strong rival off the competitor list and your slice of the remaining mentions looks bigger. Even innocent choices distort it: in published tests, rewording prompts with synonyms alone has swung the measured share by double digits. The universe of buyer questions is effectively infinite, and every tool samples a sliver of it and treats that sliver as the whole.
The trade press has started saying the same thing. A June 2026 Search Engine Land analysis of the metric put it plainly: vendors "select a small, arbitrary subset of static prompts" and roll the outputs into a global percentage, while the denominator stays hidden inside "proprietary, vendor-defined systems that are almost certainly incomplete."
This is why a single share-of-voice percentage, with no prompt set or competitor list attached, is close to meaningless. It is not that the tools lie. It is that the number is only as honest as two choices you usually cannot see.
Keeping it honest is not hard, but it has to be deliberate:
- Fix the prompt set to real buyer questions, write it down, and do not quietly swap prompts between reports.
- Count the full competitor set, including newcomers the AI already recommends, not just the rivals you prefer to measure against.
- Disclose both. A share-of-voice number you cannot reproduce is an opinion, not a measurement.
What Counts as a Good Share of Voice?
There is no universal benchmark, and the clearest proof is that nobody agrees on one. Across the guides ranking for this term, "good" lands anywhere from 20% to 50% to 70%, and at least one argues 15% can mean leadership in a crowded market. They disagree because each is built on a different denominator and a different category.
Public reference points are starting to appear. Semrush's free AI Visibility Index ranks brands by share of voice across ChatGPT and Google AI Mode, built from a panel of 2,500 prompts and weighted by mention position. It will not settle what "good" means for your category, but it is the rare thing in this metric: a denominator someone disclosed.
Here is our rough read of the bands most guides converge on; treat them as orientation, not an industry standard. Use them as orientation, not targets:
| Share of voice | Rough read |
|---|---|
| Under 15% | Emerging, or invisible, depending on category size |
| 15-30% | Competitive presence |
| 30-50% | Strong category visibility |
| 50%+ | Category dominance |
Read those loosely. In a two-horse market, 50% is just parity. In a field of twenty, 15% can be the lead. A startup against entrenched incumbents might be thrilled with 12%; for the category leader, 12% is an alarm.
What tells you something is not the absolute number but two comparisons: your own trend over time, and your share against the specific competitors you named, split by whether the prompts are branded or non-branded. A share of voice climbing quarter over quarter while a named rival slips is a real result. A flat 30% with no history and no competitor context tells you almost nothing.
Why It Swings: Per-Engine and Per-Run
Two forces move your share of voice even when your brand has not changed.
The first is the engine. The same brand can hold 35% in ChatGPT and 8% in Perplexity, because each model draws on different sources and weights them differently. The engines do not even agree on whether to name brands at all: in a BrightEdge analysis of ecommerce prompts (October 2025), 99.3% of ChatGPT responses named brands, close to six per answer, while only 6.2% of Google AI Overviews named any. And when Trakkr compared brand rankings across eight models (March 2026), they agreed 43.9% of the time on average, with all eight picking the same first recommendation in just 4% of cases. A single blended number averages that gap away and hides the one finding you can act on: which engine you are losing. Read share of voice per engine first, then blend if you must.
The second is chance. AI answers are probabilistic, so the same prompt returns different brands on different runs. A recent statistical study of generative search measurement argues that visibility metrics should be treated as sample estimates of a distribution, not fixed values, and that single-run numbers look misleadingly precise. Separate research on language models found measured accuracy can vary by up to 15% across repeated runs even at identical settings. The fix is the one pollsters use: sample many prompts, repeat the runs, and report the trend with its wobble, not one reading carried to the decimal.
This is the discipline behind a good AI rank tracker: a fixed prompt set, run on a schedule, read as a trend.
Share of Voice Isn't Sentiment
Share of voice counts how often you are named. It says nothing about how you are described.
You can own 40% of the mentions in your category and still be losing, if the AI keeps framing you as the expensive option, the legacy choice, or the one with the support complaints. Volume and favorability are different axes, and a share-of-voice number flattens them into one.
This is why mature measurement layers AI brand sentiment on top: not just your share of voice, but your share of positive voice. A mention where the AI actively recommends you is worth far more than one where you are the cautionary example. In published sentiment analyses, only a minority of AI brand mentions are clearly positive, so the gap between "mentioned" and "recommended" is wide enough to matter.
If your share of voice is healthy but conversions are not, sentiment is the first place to look. You may be in the answer and still be the brand the answer warns against.
The Hidden Zero: Reachability
There is one share-of-voice reading that fools almost everyone: zero.
A 0% share of voice looks like a content or PR failure, a sign that competitors simply out-mentioned you. Often it is something more basic: the AI never read your page. If a crawler is blocked in robots.txt, stopped at a firewall, or served a page that only renders after JavaScript the bot does not run, you are not losing the share-of-voice race; you were never in it. Your pages are absent from the pool the model draws on.
The two failures look identical in a report and have opposite fixes. One is solved by better content and earned mentions; the other by a one-line change to a robots file or a firewall rule. In the scans we run, reachability is the most common cause of a flat zero, and few share-of-voice dashboards surface it, ours included; that is why the readiness check is a separate, free gate.
So before you read anything into a low number, confirm the engines can actually fetch and render your pages. Each AI crawler is its own user agent, and any of them can be blocked by accident. Rule out the hidden zero first.
How to Grow Your AI Share of Voice
Once the number is honest and your pages are reachable, growing share of voice comes down to giving engines more reasons to name you, in more of the places they look.
Most of those places are not your own site. AI engines lean on third-party corroboration: review sites, forums like Reddit, earned media, and well-kept reference pages. A brand that shows up consistently across those sources gets named more often than one that only talks about itself. Digital PR and community presence move share of voice more than another landing page does, which is why the link building platforms that earn those mentions belong alongside your tracking.
On your own pages, the work is the same as getting cited generally: answer the buyer's question plainly and early, keep claims specific and sourced, and make your brand and its facts consistent everywhere a model might check. Our AI search playbook covers that on-page work in full, from answering plainly to making your brand unambiguous to the prompts and engines worth auditing first.
Grow the inputs, and the share follows.
Frequently Asked Questions
What is a good AI share of voice?
If you report to a client or a boss, promise process rather than a percentage: a disclosed prompt set, a named competitor list, and movement against both. Anyone promising "X% share of voice" before seeing your category's answer landscape is guessing, because the bands shift completely with the denominator.
How do you calculate AI share of voice?
Count every brand mention across a fixed prompt run and divide yours by the total, times 100. Two practical rules: accumulate at least 50 to 100 prompt-runs before trusting the percentage, and lock your counting method (any mention, citation, or weighted position) in writing before the first report, so the definition cannot drift between months.
How is AI share of voice different from traditional share of voice?
The practical difference is cost and control. Traditional share of voice meant buying media-monitoring or panel data, expensive but standardized; the AI version can be computed by hand from prompt runs, cheap but easy to bias. You inherit the analyst's job the panel used to do: keeping the method honest.
Why do two tools report different share of voice for my brand?
Because each tool picks its own prompt set, competitor list, engines, and counting method (mentions versus citations versus weighted position). Any one of those choices moves the number, so two reputable tools can both be "right" and still disagree. Compare a score only against itself over time, never across tools.
Is AI share of voice a vanity metric?
It becomes one when it is a single percentage with no prompt set, no competitor list, no per-engine split, and no sentiment behind it. It becomes useful when the method is disclosed and reproducible, the competitor set is honest, and you read it as a trend tied to high-intent prompts rather than a number to celebrate.
Does Google track AI share of voice?
In a limited way, yes. Google added "share of voice" to its AI Performance Insights in Merchant Center, announced at Google Marketing Live 2026, benchmarking a brand's visibility across AI-driven shopping experiences in Search and Gemini. It is rolling out by region and scoped to shopping, not a general live metric for every site. Google's other new reports measure you, not your share: Search Console added generative AI performance reports in June 2026 (impressions in AI Overviews and AI Mode, no clicks or queries yet, subset of sites first), and GA4 added a native AI Assistant traffic channel in May 2026. Neither benchmarks you against competitors. Read all of it as a sign the metric is going mainstream, not as a universal source of truth.
Where to Start
Before you trust any share-of-voice number, settle the one input every tool takes for granted: whether the AI engines can read your pages at all. geotoolbox's free AI-Readiness Score flags a crawler block in seconds, and the AI search checker fetches your page as the major AI crawlers, flags a render gap, and grades how citable it is. Clear that first, fix a stable prompt set and an honest competitor list, then track your share over time so the number you report is one you can defend.
Sources
- Quantifying Uncertainty in AI Visibility: A Statistical Framework for Generative Search Measurement - Ronald Sielinski, arXiv, 2026 -
arxiv.org/abs/2603.08924 - Non-Determinism of "Deterministic" LLM Settings - Atil et al., arXiv, 2024 -
arxiv.org/abs/2408.04667 - Binet presents fast, cheap, predictive Share of Search metric - IPA, EffWorks Global 2020 -
ipa.co.uk/news/binet-presents-fast-cheap-predictive-share-of-search-metric - Share of Search - IPA (thirty-case-study share-of-search to share-of-market correlation) -
ipa.co.uk/news/share-of-search - AI Performance Insights in Merchant Center - Google Merchant Center Help -
support.google.com/merchants/answer/17117204 - Google launches AI Performance Insights in Merchant Center - Search Engine Land, 2026 -
searchengineland.com/google-launches-ai-performance-insights-and-conversational-attributes-in-merchant-center-478108 - The problem with AI share of voice and 3 metrics that matter more - Dan Taylor, Search Engine Land, June 2026 -
searchengineland.com/ai-share-of-voice-metrics-that-matter-more-479611 - How AI Engines Choose Brands: Citation Patterns Revealed - BrightEdge, October 2025 -
brightedge.com/resources/weekly-ai-search-insights/how-different-ai-search-engines-choose-which-brands-to-recommend - Different Models, Different Favorites - Trakkr, March 2026 -
trakkr.ai/blog/different-models-different-favorites - AI Visibility Index - Semrush -
ai-visibility-index.semrush.com - Introducing Search Generative AI performance reports in Search Console - Google Search Central Blog, June 2026 -
developers.google.com/search/blog/2026/06/gen-ai-performance-reports - New AI Assistant traffic measurement - Google Analytics What's New, May 2026 -
support.google.com/analytics/answer/9164320