llms.txt has gone from an obscure proposal to a checkbox in half the SEO plugins, usually sold as "the robots.txt for AI." So do you actually need one? The short version: most marketing sites can skip it, while documentation and developer sites should not.
robots.txt is the file that actually gates crawlers
Unlike llms.txt, robots.txt decides whether AI crawlers can fetch you at all. The free AI Crawler Checker shows which of 34 AI crawlers yours allows or blocks.
What llms.txt Actually Is
llms.txt is a plain markdown file you place at the root of your site, at /llms.txt. The developer Jeremy Howard proposed it on September 3, 2024, to solve a specific problem: an AI model has a limited context window, and a full website, with its navigation, ads, and JavaScript, is too big and too messy to feed in cleanly. The file is meant to be a curated map, a short list of your most important pages in a format a model can read without parsing your whole layout.
The format is simple. An H1 with your site name, an optional one-line summary in a blockquote, then H2 sections listing links to your key pages with short descriptions. There is also an "Optional" section for links a model can skip when it is short on space. That is the whole spec.
One thing worth getting straight up front, because most guides blur it: the spec says llms.txt is meant to help a model "use a website at inference time," which means when a person hands your site to ChatGPT or Claude and asks about it. The proposal makes no claim that search engines rank you higher for having one, and no claim that any AI engine actually reads it. It is a suggestion for how sites could expose content to models, not a standard anyone has agreed to follow.
What Google Actually Says (Both Things)
A lot of the confusion around llms.txt comes from Google appearing to say two opposite things. Google Search is blunt about it. Its AI features documentation states that "you don't need to create new machine readable files, AI text files, or markup to appear in these features," and that there are no special optimizations required for AI Overviews or AI Mode beyond being indexed and eligible for a snippet. In other words, llms.txt does nothing for your visibility in Google's AI search. John Mueller of Google put it more plainly, comparing the file to the old keywords meta tag: a claim a site makes about itself that a crawler can simply ignore and verify by reading the actual page.
Then there is the other Google. Chrome's Lighthouse now includes an llms.txt audit, which looks like an endorsement until you read the category it sits in. It is filed under "Agentic browsing," not SEO, and it only flags a problem if your llms.txt returns a server error. A missing file is marked "not applicable," because, in Google's own words, the file is "optional at the moment." The framing is about agent efficiency, helping an AI agent understand your structure faster, not about ranking.
So it is not a contradiction. It is two teams answering two different questions. The search team is telling you llms.txt will not get you cited. The agentic-browsing team is saying it might help an AI agent crawl you more efficiently someday. Neither one calls it a ranking signal, and both call it optional.
A January 2026 episode shows how little weight the file carries even inside Google. The CMS behind Google's developer docs started generating llms.txt files, so the file appeared across many Google properties; the Search team promptly removed it from its own docs while other teams left theirs up. When Mueller was asked on Bluesky whether the file still live on ai.google.dev was an endorsement, his answer was "to be direct, no."
Does It Actually Work? What the Data Shows
Set the theory aside and look at what people have measured. The picture is one-sided for the use case most site owners care about, which is getting picked up by AI search.
| The claim | What the measured evidence shows | Source |
|---|---|---|
| AI search bots read your llms.txt | A file on Search Engine Land logged zero visits from GPTBot, ClaudeBot, PerplexityBot, or Google-Extended across roughly ten weeks of server logs (August to October 2025); later log studies found the same near-zero interest: 84 requests out of 62,100 AI bot visits in a 90-day test (February 2026), and 408 requests out of 515 million AI bot events across the brands Limy monitors (May 2026) | Semrush / OtterlyAI / Limy |
| It boosts AI citations or traffic | "No evidence that llms.txt improves AI retrieval, boosts traffic, or enhances model accuracy"; SE Ranking's November 2025 study of nearly 300,000 domains found the same: removing llms.txt from its citation-prediction model made the predictions better, not worse | Ahrefs / SE Ranking |
| Major AI providers support it | None have committed to parsing it; Google's John Mueller: none of the AI services have said they use it. Search Engine Land re-checked in January 2026: not OpenAI, not Anthropic, not Google, not Meta | Google / Ahrefs / Search Engine Land |
| Adoption is already mainstream | 10.13% of nearly 300,000 domains in SE Ranking's November 2025 study had one, spread almost evenly across the web rather than clustered among top domains; an earlier July 2025 crawl had found only 951 publishers | SE Ranking; NerdyData, via Semrush |
Ahrefs' content director Ryan Law called it "a solution in search of a problem," and Semrush's verdict after running a live test was that it is "probably not worth your time right now, unless you're just curious and want to experiment." The most direct outcome test to date points the same way: Search Engine Land tracked ten sites for 90 days before and after adding the file (January 2026), and eight showed no measurable change, one declined, and the two that gained AI traffic owed it to a PR campaign and new content rather than the file. OtterlyAI, after its own 90-day log test, went a step further and removed the llms.txt check from its GEO audit entirely (February 2026). For AI search visibility, that is the state of the evidence: it does not appear to do anything yet.
There is one real exception, and it is the reason the file is not pure hype. AI coding assistants that pull documentation into their context fetch and use llms.txt; docs platforms like Mintlify generate it automatically for the sites they host, which is the one adoption path with vendor documentation behind it rather than measured logs. That is why the well-known early adopters (Anthropic, Stripe, Mintlify) are almost all developer-documentation sites. The mistake is generalizing from them. Their adoption gets quoted as proof that llms.txt works for everyone, when what it actually shows is that it works for technical docs that machines consume directly.
So Should You Bother? The Decision Rule
You do not need a strategy meeting for this. Four situations settle it.
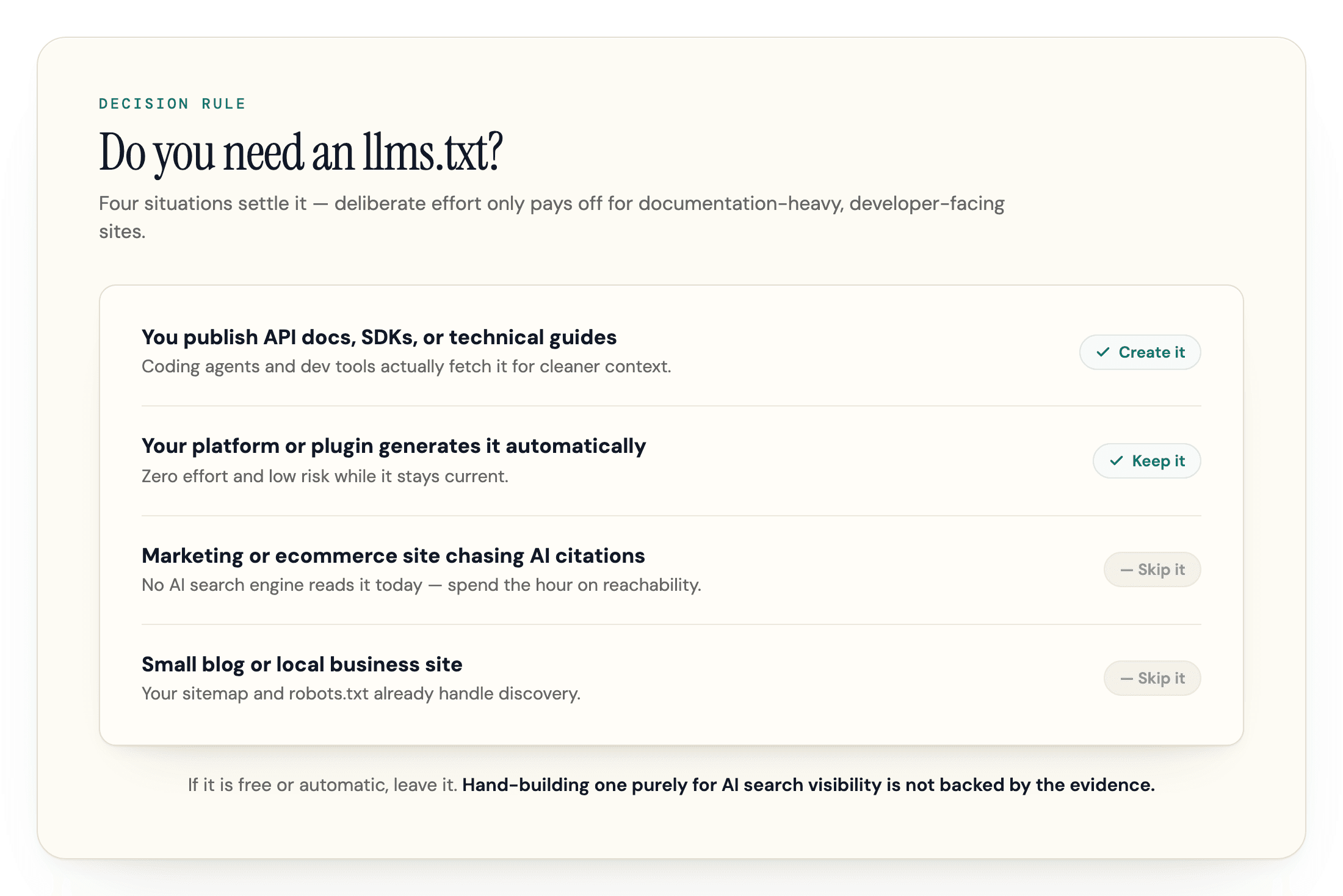
| Your situation | Verdict | Why |
|---|---|---|
| You publish API docs, SDKs, or technical guides people paste into ChatGPT or Claude | Create it | Coding agents and dev tools fetch it, per the platforms that generate it, and it gives them cleaner context about your product |
| Your platform or plugin generates it automatically (GitBook, an SEO plugin, or a docs platform like Mintlify) | Keep it | Zero effort and low risk while it stays current, and you are covered if adoption grows |
| You run a marketing, ecommerce, or brochure site and want AI citations | Skip it | No AI search engine reads it today; the hour is better spent on reachability and content |
| You run a small blog or local business site | Skip it | Your sitemap and robots.txt already handle discovery for the bots that matter |
The rule underneath the table: if it is free or automatic, having an llms.txt costs you nothing, so leave it. If you would have to build and maintain one by hand purely to chase AI search visibility, the evidence says do not. The only group for whom it is worth deliberate effort right now is documentation-heavy and developer-facing sites, where machines really do read the file.
How to Create an llms.txt File (The Right Way)
If you fall on the "create it" side, the spec is short and the file takes minutes. Our free llms.txt generator will do the tedious part for you: paste a domain and it builds a spec-correct file from your own sitemap, pulling real titles and descriptions and leaving out the pages that have no business in an AI index. Edit what it gives you before publishing, since the curation is the part that matters.
- Start with an H1 that is your site or product name. This is the only element the spec actually requires.
- Add a one-line summary in a blockquote directly under it, describing what the site is.
- Group your key pages under H2 sections, each one a markdown link with a short description, for example a "Documentation" section linking your quickstart, API reference, and guides.
- Add an "Optional" section at the end for links a model can skip when it is short on context.
- Save it as
/llms.txtat your domain root and confirm it loads atyourdomain.com/llms.txt.
Keep it curated. The point is to hand a model your best, most current pages, so leave out thin, duplicate, or archived URLs. A bloated file works against you.
One correction worth making, because half the guides get it wrong: llms-full.txt is not part of the official spec. It is a separate convention, popularized by docs platforms like Mintlify that generate it for hosted documentation, and it dumps your entire documentation into one large file. It can help dedicated dev-doc tools, but it is optional, it is not "the rest of the standard," and on a large site it gets too big to be useful. If you do want one, our llms.txt generator will build it alongside the index file, at a lower page count because it is so much heavier.
What the Guides Get Wrong
Beyond the llms-full.txt mix-up, a few gaps run through most llms.txt advice that are worth knowing before you publish one.
Validation is thin. The Lighthouse audit only checks whether the file loads without a server error, and it never looks at the structure. We built a free llms.txt checker to fill that gap: it validates the H1 and H2 structure against the spec and confirms every linked URL actually resolves. What no tool can do is tell you a model will parse the file the way you intend, and there is no equivalent of Search Console's robots.txt tester for that, so you are still partly publishing on faith.
The directives can collide. If you list a page in llms.txt that is also set to noindex or disallowed in robots.txt, nothing in the spec says which one wins, and you should not assume an agent resolves it the way you would. There is also a quieter trade-off: an llms.txt is a public file, so listing your highest-value pages in one hands a tidy map of them to scrapers and competitors as well as to friendly agents.
And it goes stale. A file that drifts out of sync with your real content feeds models outdated links and answers. If you cannot keep it current, an old llms.txt is worse than none.
llms.txt vs robots.txt vs Sitemap
The "robots.txt for AI" label gets repeated everywhere, and it is the wrong mental model. The three files do genuinely different jobs.
robots.txt is access control. It tells crawlers, including the AI crawlers, which paths they may fetch, and well-behaved bots obey it. Ignore a robots.txt rule and you are misbehaving. A sitemap is a complete inventory of your URLs so search engines can discover every page. llms.txt is neither. It does not control access and it is not exhaustive; it is a curated summary of your best content offered to a model on the chance it asks.
The practical difference that matters: robots.txt has teeth, llms.txt has none. A crawler that ignores your robots.txt is breaking a rule. A model that ignores your llms.txt is doing nothing wrong, because the file was only ever a suggestion. That is why it complements those older files rather than replacing either one.
Is llms.txt a Distraction from Real AI Visibility?
For most sites, a little. Not because the file is harmful, but because it absorbs attention that belongs elsewhere. The things that decide whether AI engines cite you are not exotic, and llms.txt is not among them.
Start with whether the AI crawlers can even reach and render your pages. A robots.txt rule or a firewall that blocks GPTBot, or content that only appears after JavaScript a crawler does not run, will keep you out of AI answers no matter how polished your llms.txt is. In our experience auditing sites for AI visibility, that reachability gap explains far more "we are not getting cited" cases than any missing file. After that comes the content itself: clear, answer-first pages that a model can quote. Our guide to optimizing for AI search walks through both, and the broader question of whether agents can actually use your site is covered in making your site agent-ready.
If you want to know where your hour actually goes furthest, check the access path first. Those are the parts of AI visibility that have evidence behind them.
The Bottom Line
llms.txt is a real proposal solving a real problem for a narrow audience. If you publish developer documentation, or your platform makes the file for free, having one is sensible and costs you nothing. For everyone else chasing AI search visibility, the measured evidence says it is the lowest-priority item on the list.
So treat it as what it is: a ten-minute footnote, not a strategy. The work that actually moves your standing in AI answers is making sure agents can reach, render, and quote your pages. If you only do one thing this week, run your domain through geotoolbox's free AI-Readiness Score and fix what it flags; the Content Analyzer adds the per-page citability grade. That is where the evidence points, and llms.txt can wait until the standard catches up to the hype.
Frequently Asked Questions
Does ChatGPT, Claude, or Perplexity actually read llms.txt?
You can answer this for your own site in five minutes: publish the file, wait a few weeks, and grep your server logs for requests to /llms.txt by bot user agent. Every published test so far has come back empty or close to it for the search crawlers; the largest, Limy's May 2026 analysis of 515 million AI bot events across the brands it monitors, logged just 408 requests for the file. That is stronger evidence than any vendor statement.
Where exactly does the llms.txt file go?
At the root of your domain, like robots.txt: yoursite.com/llms.txt, served as plain text or markdown with a 200 status. On WordPress, several SEO plugins write it for you; on hosted docs platforms it is usually generated automatically; on anything else it is a static file in your web root.
What's the difference between llms.txt and llms-full.txt?
llms.txt is the short, curated index defined by the spec; llms-full.txt dumps the entire documentation into one file. The practical selection rule: a coding assistant with a small context window wants the index, while a tool building a local knowledge base wants the full dump. If you only ship one, ship the index.
Should I add llms.txt to a marketing site or just documentation?
A middle case worth knowing: SaaS sites with a /docs section can serve llms.txt scoped to the docs while skipping it for the marketing pages. That gets the coding-assistant benefit where it exists without pretending the homepage needs it.
Does llms.txt affect Google indexing or my robots.txt rules?
No interaction in either direction. Googlebot indexes your pages whether or not the file exists, and llms.txt cannot override a robots.txt block: a crawler disallowed in robots.txt should not fetch your llms.txt either. Treat them as fully independent files.
Sources
- The /llms.txt file - llms.txt specification (Jeremy Howard, the proposal, format, and intent) -
llmstxt.org - llms.txt | Lighthouse - Google Chrome for Developers (the agentic-browsing audit framing) -
developer.chrome.com/docs/lighthouse/agentic-browsing/llms-txt - AI Features and your website - Google Search Central (no special files needed for AI features) -
developers.google.com/search/docs/appearance/ai-features - What Is llms.txt, and Should You Care About It? - Ahrefs (verdict and John Mueller's assessment) -
ahrefs.com/blog/what-is-llms-txt - What Is LLMs.txt & Should You Use It? - Semrush (server-log test and adoption data) -
semrush.com/blog/llms-txt - LLMs.txt: Why Brands Rely On It and Why It Doesn't Work - SE Ranking (300,000-domain adoption and citation-correlation study, November 2025) -
seranking.com/blog/llms-txt - Does llms.txt matter? We tracked 10 sites to find out - Search Engine Land (10-site before/after test, January 2026) -
searchengineland.com/does-llms-txt-matter-467740 - llms.txt and AI Visibility: Results from OtterlyAI's GEO Study - OtterlyAI (90-day server-log experiment, February 2026) -
otterly.ai/blog/the-llms-txt-experiment - LLMs.txt in 2026: The Full Guide - Limy (515-million-event crawler-log analysis, May 2026) -
limy.ai/blog/llms.txt-in-2026-the-full-guide - Google Search Team Does Not Endorse LLMs.txt Files - Search Engine Roundtable (Mueller on Google's own llms.txt files, January 2026) -
seroundtable.com/google-does-not-endorse-llms-txt-40789.html