Ask ChatGPT how many R's are in "strawberry" and it has, more than once, answered two. The model is not dim. It simply does not read words or letters the way you do. It reads tokens.
Tokens in AI are the chunks of text a model actually processes, and once you understand them, a long list of strange behavior stops being mysterious: the miscounted letters, the per-token bills, the "context length exceeded" errors, the brand names that come out misspelled. This covers what tokens are, for people who publish content rather than build models, including the part the engineering explainers skip: what tokenization does, and does not, mean for your visibility in AI search.
What Is a Token in AI?
A token is a chunk of text that an AI model treats as a single unit. It is usually about four characters, or roughly three-quarters of a word. A model does not read your words the way you do, and most of the time it does not see individual letters at all. It works in tokens.
This trips people up because tokens do not line up with words. Some short, common words are one token. Longer or rarer words get split into several. Even a space or a capital letter changes things: according to OpenAI's own explainer, the strings " red", " Red", and "Red" are three different tokens. The model sees three different things where you see one word.
The rules of thumb worth memorizing come from the same source. One hundred tokens is about 75 words. The sentence "You miss 100% of the shots you don't take" is 11 tokens in OpenAI's tokenizer. These ratios are averages, not laws, and they shift with the language and the content, but they are close enough to reason with.
| Tokens | Approx. words (English) | Approx. characters | Rough scale |
|---|---|---|---|
| 1 | ~0.75 | ~4 | part of a word |
| 100 | ~75 | ~400 | a short paragraph |
| 1,000 | ~750 | ~4,000 | a long blog section |
| 100,000 | ~75,000 | ~400,000 | a short book |
| 1,000,000 | ~750,000 | ~4,000,000 | ~10 novels |
Why should anyone publishing content care? Because tokens are the unit behind almost everything an AI system does to your text: how much of your page a model can hold at once, how its owner gets billed, and why it sometimes mangles a number or a brand name. Understanding tokens is how you tell the real constraints apart from the large language model folklore.
Not the crypto kind
If you searched "AI tokens" and landed on coin prices, that is a different meaning entirely. Crypto "AI tokens" are tradeable assets tied to AI projects. The tokens in this article are units of text. Same word, unrelated topic.
How Tokenization Works: From Text to Token IDs
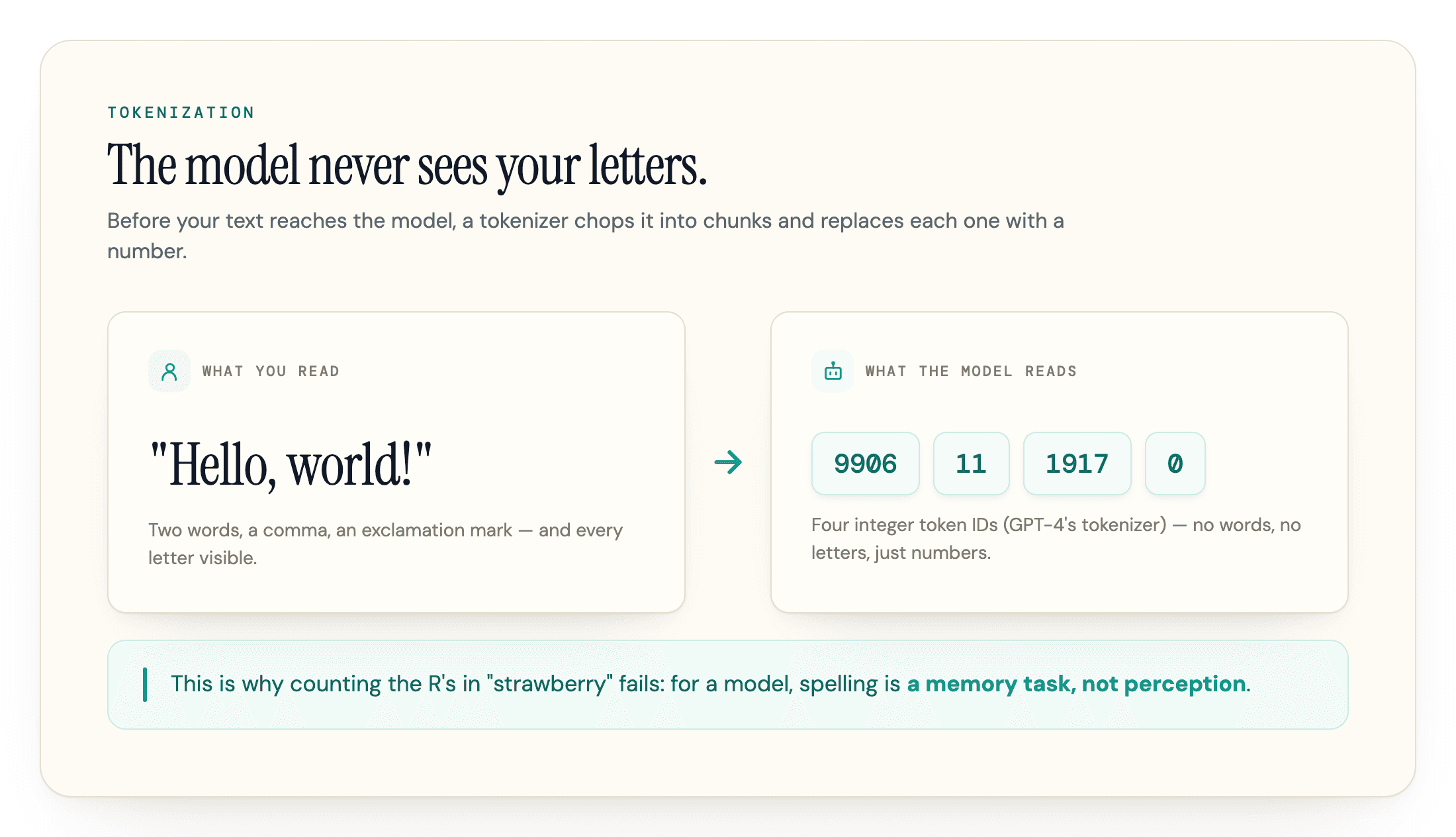
Before your text ever reaches the model, a separate program called a tokenizer chops it into tokens and replaces each one with a number. "Hello, world!" does not enter the model as words. It enters as a short list of integer IDs, something like [9906, 11, 1917, 0] (those are GPT-4's tokenizer; a newer model assigns different numbers). The model works with the numbers. The model usually receives tokenizer IDs rather than a native character stream; the useful character-level structure is not directly exposed as separate letters.
The splitting follows a method called subword tokenization. Frequent words get their own single token. Rare words, brand names, and long compounds get broken into pieces. "Tokenization" might split into "token" and "ization." A made-up product name might shatter into four or five fragments, which is why models sometimes garble an unusual brand name: they are rebuilding it from parts, not recalling it whole. The tokenizer is not reading for meaning, just matching against a fixed vocabulary of known chunks built once, in advance. Images and audio get the same treatment in multimodal models, sliced into patch and audio tokens, so the logic here carries over.
That vocabulary comes from an algorithm called byte pair encoding (BPE), a 1990s data-compression trick that Sennrich, Haddow, and Birch adapted for neural text models in 2016. BPE starts from individual characters and repeatedly merges the most common neighboring pairs until it has a vocabulary of the desired size. GPT-2 settled on 50,257 tokens. The GPT family still uses BPE, through OpenAI's tiktoken library (the cl100k_base vocabulary for GPT-4, o200k_base for GPT-4o). Other model families use close cousins: WordPiece for BERT, SentencePiece for Gemini- and earlier Llama-class models.
Here is the part that matters for everything downstream. Tokenizing is only step one. Each token ID is then mapped to a vector embedding, the list of numbers that actually carries meaning. Token, then ID, then vector. The token is the raw cut. The embedding is where understanding starts.
Why ChatGPT Can't Count the R's in "Strawberry"
The famous failure where a model insists "strawberry" has two R's comes straight from tokens. The word arrives as a handful of subword tokens, and not one of them is a letter. The model usually receives tokenizer IDs rather than a native character stream; for a word like "strawberry," the useful character-level structure is not directly exposed as separate letters. It sees two or three opaque IDs and is asked to count something it cannot look at directly.
So spelling questions are really memory tasks for a model, not perception. To count the R's, it has to recall how the word is spelled from its training data, then count over the recalled letters, and both steps can go wrong. It is like being asked how many times the letter E appears in a word you have only ever heard out loud.
Tokens are not the whole story, to be fair. Ask a model to spell "strawberry" and it usually can, then it still miscounts, which means the counting step fails on its own. Tokens are why the task is hard. They are not the only reason it goes wrong.
Arithmetic breaks for a related reason. Long numbers get chopped into tokens at arbitrary points, so "1234567" might split into pieces that do not line up for digit-by-digit math. That is part of why models have fumbled questions like whether 9.11 is bigger than 9.9. And there is only a fixed amount of computation per token, nothing like the open-ended loop you would use to carry digits through a long sum.
Newer models look better at this, but be precise about why. A common workaround is to spell the word out or separate the letters, making the character-level task easier for the model. It is a workaround, not a fix at the tokenizer level. As of late 2025, reports were still catching GPT-5.2 miscounting some variants. By mid-2026 the newest flagships usually pass the famous "strawberry" test, largely because that exact case is now familiar to them. They can stumble on less familiar, misspelled, or invented words, since subword tokenization keeps the letters out of direct reach. This is the same family of gap behind other AI hallucinations: the model confidently reports something its architecture did not actually let it check.
The same blind spot explains a pain every writer has hit: ask for 1,000 words and you often get 700, with the model insisting it delivered 1,000. It generates token by token with no running word counter, so it cannot track its own length any better than it can count R's. Treat anything character-level or count-based the same way, from reversing a string to solving Wordle, and lean on models for meaning rather than spelling.
Tokens, Context Windows, and Memory
A model's context window is the most you can put in front of it at once, and it is measured in tokens, not words or pages. Everything has to fit inside that budget: your prompt, any documents you paste, the system instructions you never see, and the answer the model is about to write. When people say a model "remembers" a long conversation, what they mean is the whole conversation still fits in the window.
These windows have grown fast, and they keep moving, so treat any single number as a snapshot. The trajectory by era:
| Model (era) | Approx. context window |
|---|---|
| GPT-3 (2020) | ~2,048 tokens |
| GPT-4 (2023) | ~8,000 to 32,000 tokens |
| GPT-4o (2024) | ~128,000 tokens |
| Claude 3 and 3.5 (2024) | ~200,000 tokens |
| Gemini 1.5 Pro (2024) | up to ~1 to 2 million tokens |
| Frontier models (2026) | ~1 million, a few far higher |
By mid-2026 a dozen-plus frontier models ship windows of a million tokens or more, and the largest open-weight model advertises 10 million. One honest caveat the marketing skips: usable context runs smaller than the advertised number, so a million-token window does not buy a million tokens of reliable attention.
When you blow past the window, the system does not warn you politely. An API may throw a context-limit error, while chat products may truncate, summarize, compact, or otherwise manage older context, which is why a long session can seem to forget how it started or lose the top of a document you pasted. You cannot count on any one behavior. The only guarantee is that the full original text no longer fits.
This is also where tokens meet AI search. When ChatGPT or a Google AI Overview answers a question, retrieval-augmented generation fetches passages from the web and stuffs them into that same token budget before the model writes a word. The context window is finite, so the system keeps only the passages it ranks highest. Your content is competing for room measured in tokens.
How Token Pricing Works, and Why Each Reply Costs More
When a company builds on an AI model through its API, it pays by the token, usually quoted as a price per million tokens. Two details surprise people. First, output tokens cost more than input tokens, often several times more, because generating text one token at a time is the expensive part. Reading your prompt is cheap. Writing the answer is not.
Second, a chat does not bill only your latest message. To answer turn five, the model re-reads turns one through four, so the whole conversation so far rides along and is charged again, which is why a long back-and-forth gets more expensive with every reply. It is also why an agent that reloads its whole context on every step can run up a bill fast. Providers now discount repeated text through prompt caching, but the structure stands: the history travels with every turn. Hidden inputs add up the same way, from the system prompt to any internal reasoning tokens a model burns before its visible answer.
There is one real cost lever here, and it is worth naming precisely so it does not get misapplied. Trimming filler out of prompts and instructions can cut API spend, with one security firm putting the savings around 10 to 30%. That is a genuine practice, but it lives entirely on the application-building side. It is about the prompts a developer sends, not the web copy you publish. Hold that distinction, because the SEO world routinely blurs it.
How many tokens is a dollar?
There is no fixed answer, since rates differ by model and change often, but the order of magnitude holds. At the few-dollars-per-million-tokens rates common in 2026, a dollar buys somewhere in the hundreds of thousands of input tokens, on the order of a few hundred pages of text. Output, priced higher, buys less.
One more clarification, since it is the question behind a lot of confusion: a ChatGPT Plus subscription is a flat monthly fee, not per-token billing. Per-token pricing is the API world. Most people writing content never touch it directly.
The Non-English Token Penalty
Tokenizers are not neutral across languages, and the gap is large. The same sentence translated out of English can take far more tokens to represent, because the tokenizer's vocabulary was trained mostly on English text and has fewer ready-made chunks for everything else. A study by Petrov and colleagues found the token count for the same content can run up to roughly 15 times longer in some languages than in English.
The penalty scales with how far a language sits from English and which tokenizer is doing the cutting. Many European languages land around one and a half to three times the token count. Languages written in non-Latin scripts, like Arabic and Hindi, run higher still, and severely under-resourced languages fare worst. In some cases a word produces more tokens than it has letters.
For anyone publishing or budgeting AI work in more than one language, this is a real line item. The same content costs more to process, and it eats more of the context window, in nearly every language the studies have measured.
Do Tokens Affect Your AI Search Visibility?
This is where the topic gets sold badly, so here is the honest answer. Tokenization is not a dial you can turn. You do not pick the tokenizer. You can inspect an open one like OpenAI's to see how it splits a sample, but you cannot change it, and the closed retrieval pipelines behind AI search split and select pages in ways they never publish. Any advice that tells you to write "for the tokenizer" is selling a control that does not exist on your side.
What is real sits one layer up. AI search shortlists content by meaning, comparing the embeddings of your passages against a query using semantic search. Passages that are clear and self-contained tend to retrieve better. But that is just good writing. It is the same advice that worked before anyone said the word token, and it has a mechanism behind it, not a trick.
A few claims to retire. "Chunk your content into token-sized pieces" is one Google's own AI features guidance now calls unnecessary, the same point we make about content chunking. "Token-optimize your copy to rank in AI" borrows the API cost practice from the pricing section and pretends it applies to web content, with no evidence behind it. "Pick a token-friendly brand name so AI spells it right" is another: a heavily split name can wobble, but renaming your company around a tokenizer you cannot see is not a strategy. And "one token equals one word" is simply wrong, as the first table showed.
In our experience at geotoolbox, the people most confused here have read genuine engineering advice about cutting token costs in an app and assumed it must apply to their blog. It does not. What you actually control sits above the tokenizer, in whether your pages are clear, retrievable, and reachable, which is what our guide to optimizing for AI search is about.
Frequently Asked Questions
How many words is 1,000 tokens?
About 750 words of English. The rule of thumb is one token to roughly three-quarters of a word, so a 1,000-token reply runs about two paperback pages. Punctuation, rare words, and other languages shift the count, but 750 is close enough to plan around.
Why can't ChatGPT count the letters in "strawberry"?
Because the word reaches it as a few subword tokens, with the useful character-level structure not directly exposed as separate letters, so counting R's is recall-and-tally from memory rather than something it can read off the page. Models that answer correctly usually write the word out letter by letter first, which is a workaround, not a cure.
How do I check how many tokens my text uses?
Use a tokenizer tool. OpenAI's free Tokenizer shows the exact split for GPT models, and its tiktoken library does the same in code. For other model families, Hugging Face's Tokenizer Playground covers most open tokenizers. Counts differ between families, so a number from one tokenizer is only an estimate for another.
Do I pay for tokens in ChatGPT?
Not in the consumer app. A ChatGPT subscription is a flat monthly fee with usage limits. Per-token billing is the API world, where a business pays separately for the tokens it sends in and the tokens the model writes back.
What happens when I hit the token limit?
In an app you get a "context length exceeded" error; in a chat, the oldest turns usually fall away. If you hit it, start a fresh chat, paste back only the part that matters, or ask for a summary you can carry forward. A model with a larger context window buys you room, not immunity.
Is an "AI token" a cryptocurrency?
No. These are two unrelated meanings. In AI, a token is a unit of text a model processes. In crypto, "AI tokens" are tradeable digital assets attached to AI projects. This article is only about the text kind.
What Tokens Actually Change for You
Tokens are a diagnosis, not a dashboard. They explain why the machine miscounts, truncates, and bills the way it does. The controls all sit somewhere else.
The earliest one is access. If an AI crawler cannot reach your page, none of this token machinery ever runs on it, because the page never enters the budget. That gate you can actually test: our free AI Readiness check shows whether the relevant search crawlers and user agents for ChatGPT Search, Perplexity, and Google Search AI features can reach a page, and what is blocking them when they cannot. Tokens tell you how the machine reads. Reachability tells you whether it reads you at all.
Sources
- OpenAI Help: What are tokens and how to count them -
help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them - OpenAI Tokenizer (interactive tool) and tiktoken (library) -
platform.openai.com/tokenizer-github.com/openai/tiktoken - Sennrich, Haddow & Birch (2016): Neural Machine Translation of Rare Words with Subword Units (byte pair encoding) -
arxiv.org/abs/1508.07909 - Petrov et al. (2023): Language Model Tokenizers Introduce Unfairness Between Languages -
arxiv.org/abs/2305.15425 - Dataconomy: GPT-5.2 still counts two R's in strawberry -
dataconomy.com/2025/12/15/gpt-5-2-still-counts-two-rs-in-strawberry - Google Search Central: Guidance on AI features and generative AI -
developers.google.com/search/docs/fundamentals/ai-optimization-guide - Pivot Point Security: AI tokens and how they impact usage costs -
pivotpointsecurity.com/ai-tokens-how-they-impact-usage-costs - Artificial Analysis: AI model comparison, including context windows (2026) -
artificialanalysis.ai/models