Vector embeddings are the math that decides which content AI search engines retrieve when they assemble an answer. The explainers that rank for this topic teach developers how to build with them. This one covers what they mean for people who publish content: how the numbers work, how engines use them to shortlist what gets cited, and which parts of "embedding optimization" are real versus repackaged.
What Are Vector Embeddings?
Vector embeddings are numerical representations of content. An embedding model takes a piece of text (or an image, or audio) and converts it into a long list of numbers, called a vector, that captures what the content means. Two passages that mean similar things get vectors that sit close together in mathematical space. Two passages about unrelated topics end up far apart.
That one property, meaning encoded as distance, is the entire trick. Software cannot compare two paragraphs the way you do. It can compare two lists of numbers instantly. Embeddings turn "is this passage about the same thing as that query?" into a math problem with a precise answer.
A single vector embedding looks like this: [0.012, -0.738, 0.291, ...], running for hundreds or thousands of values. No individual number means anything on its own. The pattern across all of them is what encodes the meaning, the same way no single pixel makes a photo.
Why should you care as an SEO or content marketer? Because ChatGPT, Perplexity, and Google AI Overviews all depend on retrieval to choose what they cite, and embeddings are core machinery in modern retrieval. When an AI engine decides which passages from the web get pulled into an answer, similarity between the question's embedding and your content's embedding is part of how candidates get shortlisted.
In other words: embeddings are the mechanism behind the advice you have already heard. "Write clearly." "Cover one idea per section." "Use consistent terminology." Those recommendations work in part because of how this layer of the pipeline behaves. Understanding it lets you separate the advice that has a mechanism behind it from the advice that is made up.
How Do Vector Embeddings Work?
Nobody writes embeddings by hand. They come out of embedding models, machine learning algorithms (modern ones are neural networks) trained on enormous amounts of text until they learn which words and phrases occur in similar contexts.
How does a model learn meaning? From context. Train on enough text and the words that keep appearing in similar surroundings end up placed near each other, positions that mirror their semantic relationships. The resulting geometry supports arithmetic that feels almost too clean: in Jay Alammar's illustrated walkthrough of word2vec-era word embeddings, taking the vector for "king," subtracting "man," and adding "woman" produces a vector whose nearest named neighbor is "queen" (the classic demo excludes the input words themselves, a caveat worth knowing before you repeat it on stage). The directions inside the space correspond to real concepts, like royalty or gender, even though no one programmed them in.
Here's the thing about dimensions. Each vector has a fixed length, and that length is the model's dimension count. BERT uses 768 dimensions in its base version and 1,024 in its large one (768 is an architecture choice, attention-head size times head count, not a magic number). OpenAI's embedding models output 1,536 dimensions for text-embedding-3-small and 3,072 for text-embedding-3-large. More dimensions can capture finer distinctions, at the cost of storage and speed, which is why OpenAI lets developers shorten vectors through a dimensions parameter rather than always running at full size. (And no, the embedding size GPT-4 uses internally is not published, whatever a tool vendor told you.)
Early models like word2vec and GloVe were static: one word, one vector, forever. That breaks on ambiguous words, because "set" has hundreds of senses and a single vector has to average them all. Transformer-based models like BERT fixed this. They read the whole input first, so each word's vector shifts based on the words around it. "Bank" near "river" and "bank" near "loan" produce different embeddings.
Modern embedding models apply the same idea beyond single words. They produce one vector per sentence, passage, or document, which is the form that matters for search: In many AI retrieval systems, content is chunked and stored as embeddings of passages.
Dimension count is not a quality lever
You will see vendors compare models by dimension count. More dimensions is not better content representation by default, and you do not get to choose what production engines use anyway. File this number under "how it works," not "what to optimize."
A Worked Example: How Similarity Gets Measured
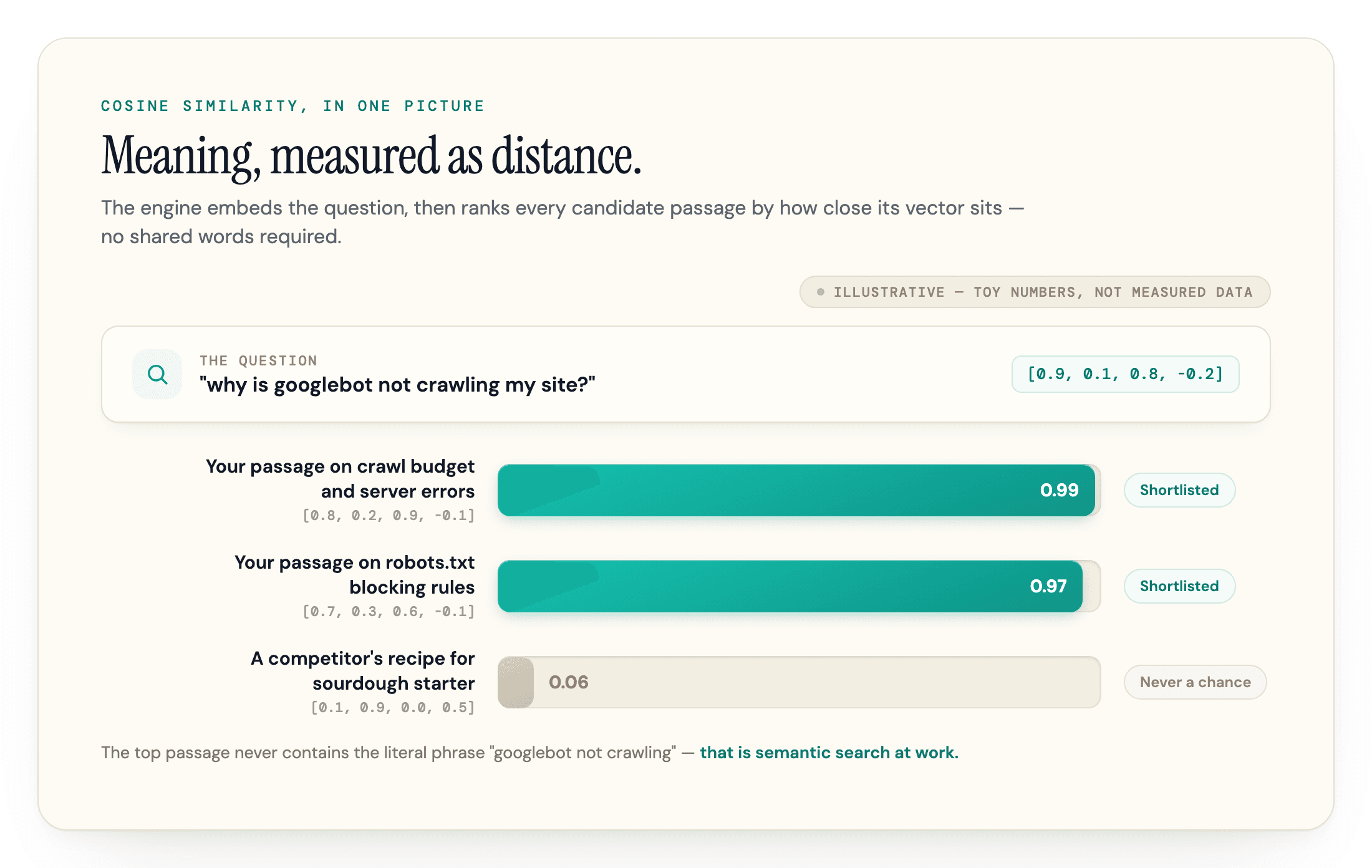
Say someone asks an AI assistant: "why is googlebot not crawling my site?" The engine embeds that question, then compares it against embeddings of indexed content. Here is a toy version with 4 dimensions instead of 1,536 (the numbers are invented to show the mechanics, real vectors are far longer):
| Content | Toy embedding | Similarity to query |
|---|---|---|
| Query: "why is googlebot not crawling my site" | [0.9, 0.1, 0.8, -0.2] | - |
| Your passage on crawl budget and server errors | [0.8, 0.2, 0.9, -0.1] | 0.99 |
| Your passage on robots.txt blocking rules | [0.7, 0.3, 0.6, -0.1] | 0.97 |
| A competitor's recipe for sourdough starter | [0.1, 0.9, 0.0, 0.5] | 0.06 |
The score in the last column is cosine similarity: a measure of the angle between two vectors. The scale runs from 1 (same direction, same meaning) down through 0, with unrelated content landing near zero. (In real embedding spaces even unrelated text rarely scores strongly negative, and older models like ada-002 compress everything into a narrow positive band, so when you run this yourself expect smaller gaps than a toy example shows.) OpenAI's documentation recommends cosine similarity for comparing its embeddings, and it is the default metric across most of the industry because it compares the direction of meaning while ignoring vector magnitude. (Euclidean distance and dot product are the other metrics you will see; cosine is the standard for text.)
The retrieval step is then just sorting. The system ranks every candidate passage by similarity score and takes the top handful, its nearest neighbors, as the shortlist for the answer (production systems use approximate nearest neighbor algorithms to do this fast across millions of data points). Both of your technical SEO passages make the cut. The sourdough recipe never had a chance.
Notice what made the difference: the crawl-budget passage scored highest because its content concentrates on exactly what the question asks. That is semantic search at work. The passage did not need to contain the literal phrase "googlebot not crawling" anywhere.
How AI Search Engines Use Embeddings to Pick What They Cite
When an AI engine answers a question with citations, embeddings have usually done the heavy lifting before the model writes a single word. The pipeline looks like this:
- Your question gets embedded. The engine converts the query into a vector using the same embedding model it used to index content (often after fanning one prompt out into several sub-queries). In practice the query must use the index's model: raw vectors from different models live in different spaces and are not directly comparable.
- Candidates get retrieved. The engine runs a similarity search against its index and pulls the passages whose embeddings sit closest to the query vector.
- Candidates often get reranked. A second model OR ranking system may rescore the shortlist with more expensive checks for relevance, and systems layer in signals like freshness and authority.
- The model writes, citing a subset. The generator reads the surviving passages and composes an answer, attributing some of them as sources.
One documented exception to note: Google states that AI Overviews grounding pulls candidates through its core Search ranking systems (with AI Mode adding query fan-out), so embeddings work inside classic ranking there rather than as a standalone vector index. ChatGPT Search and Perplexity APPEAR closer to the pipeline above, based on observed behavior; live web-search internals are not fully published.
This is the retrieval-augmented generation pattern, and it is worth reading our breakdown of how AI search works for the full pipeline. The short version: retrieval-augmented generation grounds the model in retrieved passages instead of letting it answer purely from training memory. For the full explainer, see what RAG is.
Two implications get missed constantly.
Retrieval is not citation. Embedding similarity gets you onto the shortlist in step 2. It does not decide who gets credited in step 4. A passage can be retrieved and never cited, outranked at the last step by a clearer or more authoritative competitor. Embeddings decide who is in the room, not who gets quoted.
Pure vector search is not how production systems actually run. Production search stacks pair classic keyword scoring (BM25) with vector similarity and merge the results. Microsoft's Azure AI Search documentation is explicit that exact-match queries like product codes, specialized jargon, and names perform better with keyword search, and reports that "hybrid retrieval with semantic ranker offers significant benefits in search relevance." Anyone telling you keywords are dead is ignoring how production retrieval is built.
So does ChatGPT use embeddings? Yes, in two unrelated ways, and conflating them causes most of the confusion we see. Internally, every LLM represents tokens as vectors during processing; that is just how transformers compute.
Separately, retrieval decides what reaches the model: OpenAI documents that its file search runs on vector stores using "semantic and keyword search." Engines do not publish their live web-search internals, but this retrieval pattern is the standard mechanism for narrowing candidates there too. The internal token vectors have nothing to do with your visibility. The retrieval layer is where your content competes.
You do not need to be in training data to get cited
Training data and retrieval are different doors. A page published yesterday can be retrieved and cited today, because retrieval reads the live index, not the model's training snapshot. That is the entire reason AI visibility is workable as a discipline instead of a five-year wait.
What Embeddings Mean for How You Write and Structure Content
The single most useful thing to internalize: modern AI retrieval systems OFTEN chunk and embed passages, not just whole pages. Your 3,000-word guide may be split into smaller units that compete independently for retrieval.
Part of this is a hard constraint. Embedding models cap their input (OpenAI's models take at most 8,192 tokens), and meaning gets compressed long before that limit anyway. A vector embedding forced to summarize five different subtopics ends up an average of all of them, distinctly representing none. Retrieval systems chunk content because focused chunks produce sharper vectors.
That mechanism produces three practical rules.
One idea per passage. A section that opens with its point and stays on it produces an embedding concentrated on that meaning, easier to match to the question it answers. A section that wanders across three topics produces a diluted vector that matches nothing decisively. This is the mechanical reason content chunking practices like answer-first paragraphs and self-contained sections hold up, while the "chunking hacks" sold around them do not. (Section sizing questions live in that article too.)
Make each passage survive alone. Retrieval rips your passage out of its page. If the chunk says "this setting also affects it" with no referent, the retrieved text is ambiguous on arrival. Name the subject. A passage that reads cleanly in isolation is one a reranker can score with confidence.
Keep terminology consistent. Embeddings handle synonyms far better than keyword matching ever did, but every passage still competes on how concentrated its meaning is. Calling the same feature three different names across a page spreads your semantic signal thinner than it needs to be.
These rules have at least one small-scale public test behind them. Chris Green's content-structure experiment embedded the same information in three formats and found Q&A format "consistently delivered the highest semantic relevance to queries in every scenario," with dense prose worst, alongside his own caveat that it is a small simulation and vector similarity is not ranking. Tested, narrow, honestly labeled: exactly the kind of evidence this space needs more of.
What about long-form content overall? You will hear that long pages get "averaged out" and underperform in vector search. The mechanism is plausible given how chunk boundaries fall, but we have not seen controlled public evidence that page length itself hurts retrieval once chunks are well-formed. Treat it as a claim, not a fact. The defensible version is smaller: structure your long page so every section could be lifted out and still make sense.
Can You Optimize for Embeddings? An Honest Answer
Mostly no, and the parts that work are not what the hype suggests.
You cannot see the embedding models that ChatGPT, Perplexity, or Google run in production, cannot query them directly, and cannot verify any claimed "embedding score" for your page against them. A tool that sells you a vector-similarity grade is measuring your content against a model it picked, not the model that decides your visibility. Those numbers can disagree, and you have no way to check. Treat any "optimize your embedding score" pitch accordingly.
There is also no stable target to chase. Engines swap embedding models, and a swap means re-embedding the content the new model searches over. Content tuned to quirks of one model inherits nothing when the model changes.
What does hold up is unglamorous, and it works because of the mechanism rather than against it:
Disambiguation. A passage that says "geotoolbox tracks citations across eight AI engines" embeds distinctly. A passage that says "our platform delivers results" embeds like ten thousand other vague pages. Specificity is separation in vector space.
Structure and consistency. The three rules from the previous section, unchanged. They are the closest thing to a real lever you have, which is exactly the point:
None of this is new advice. The mechanism is new; the writing has been good practice for decades. That is the strongest tell against "embedding optimization" as a discipline: when the practical recommendations are identical to clear writing, the seller is renaming fundamentals, not offering an edge.
One more honesty checkpoint. Embedding models inherit whatever their training data contains. The well-known 2016 Bolukbasi paper found that embeddings trained on Google News "exhibit female/male gender stereotypes to a disturbing extent." The OpenAI embeddings guide cited throughout this article does not mention it once, but it matters for trusting these systems blindly: similarity scores encode the biases and blind spots of the text the model learned from.
In our experience, the useful discipline is measuring outcomes instead of intermediates. You cannot audit a production engine's vectors, but you can check whether AI engines actually cite you, for which prompts, against which competitors. That is observable and tied to the thing you actually want, even if it is noisy enough that you should read trends rather than single checks.
How to See Embeddings in Action Yourself
You do not need to take any of this on faith. Two cheap experiments make the whole mechanism concrete.
Crawl your own site with embeddings turned on. Screaming Frog's SEO Spider can generate vector embeddings for every page during a crawl. Its semantic similarity tutorial walks through the setup:
- Connect an AI provider under Config > API Access > AI (OpenAI, Gemini, or a local Ollama model)
- Enable embeddings under Config > Content
- Crawl the site
- Run crawl analysis
You get a similarity score from 0 to 1 for every page against its nearest neighbor, plus filters that surface semantic duplicates and pages drifting off-topic. Note that this embeds whole pages, useful for spotting duplicates and drift, even though production retrieval mostly works on smaller chunks. Watching two pages you thought were different score 0.95 against each other is the fastest way to internalize what these vectors actually measure.
This is working practice, not a novelty. Mike King's iPullRank guide catalogs production SEO uses for crawl-generated embeddings, keyword mapping, internal linking, redirect mapping, content clustering, and SEOs have been running these workflows since before AI search made embeddings fashionable.
Embed two sentences yourself. OpenAI's embeddings endpoint costs fractions of a cent per call; its own docs work the small model out to roughly 62,500 pages of text per dollar. Send it a question your customers ask and the paragraph on your site that should answer it, compute cosine similarity between the two vectors, then try the same question against a competitor's paragraph. Ask any coding assistant for the ten-line script; you will have watched retrieval's core operation run on your own content inside half an hour.
Neither experiment shows you what production engines compute, their models and indexes are theirs. What you get is the right mental model, plus a genuinely useful site audit in the Screaming Frog case.
Once You Are Retrieved, What Wins the Citation?
Retrieval gets you into the room. The final step, which passage gets named as a source, belongs to layers the engines publish even less about.
What is observable: reranked relevance (does your passage answer the exact question), self-sufficiency (can it be quoted without the rest of its page), and source-level signals like authority and freshness that engines say they layer in. What is not published: the weights. Nobody outside these companies knows how much each signal counts, and anyone quoting exact percentages is improvising.
The practical reading: embeddings are the qualifying race, and the writing quality of the individual passage is most of the final. Our how AI search works breakdown covers the engine-by-engine differences in how that final gets judged.
Vector Embeddings vs Entities vs Semantic Search: Which Term Means What
The vocabulary around this topic is a mess, and half the confusion in SEO discussions traces back to terms being swapped mid-argument. Here is the map:
| Term | What it is | Relationship to embeddings |
|---|---|---|
| Keyword | A literal string you target and match | The complement, not the predecessor. Hybrid retrieval runs keyword and vector scoring side by side |
| Vector | Any list of numbers | In retrieval contexts, "vector" and "embedding" are used interchangeably; the embedding is the vector |
| Vector embedding | A vector that encodes meaning, produced by a machine learning model | The subject of this article |
| Entity | A specific named thing (a person, brand, product) in a knowledge graph | A largely separate layer. Entities are explicit records with defined relationships; embeddings are statistical geometry. Entity SEO works the knowledge-graph layer, not the vector layer |
| Semantic search | Search that matches meaning rather than exact words | The application. Semantic search is what embeddings make possible |
| Vector database | A database built to store and query embeddings at scale | The infrastructure. Tools like Pinecone or pgvector index millions of vectors for fast nearest-neighbor lookup |
| RAG | The architecture that retrieves passages and feeds them to a model before it answers | The pipeline that puts embeddings to work in AI search |
The distinction that trips people up most is entities versus embeddings. Both get filed under "semantic SEO," but they are separate systems. An entity is a database row: Google knows "geotoolbox" is a software product with specific properties. An embedding is a position in space: this paragraph sits near other paragraphs about AI visibility tools. You can be strong in one layer and invisible in the other, which is why the two deserve separate attention rather than one blurred "semantic" bucket.
Frequently Asked Questions
What are dense and sparse vector embeddings?
Dense embeddings are the kind discussed throughout this article: compact vectors where nearly every number carries information, produced by neural networks. Sparse embeddings are mostly zeros, with each position mapping to an explicit term, the way classic keyword indexes work under the hood. Hybrid retrieval systems use both, dense vectors for meaning and sparse signals for exact matches.
Does Perplexity work the same way as ChatGPT search?
Directionally yes: both retrieve candidate passages before answering, which is where embeddings matter. They differ in what they retrieve from. Some published overlap studies have found Perplexity's citations track Google's results far more closely than ChatGPT's do (our ChatGPT vs Perplexity comparison breaks this down), so the same page can be cited by one engine and invisible to the other.
Are vector embeddings the same as keywords?
No. Keywords are literal strings matched against an index; embeddings encode meaning so that "fix checkout errors" and "resolve payment failures" land close together despite sharing no words. Keyword research still matters in hybrid BM25-plus-vector systems: exact terms are how engines catch product names, codes, and jargon, and they remain your best evidence of what people actually ask.
Does schema markup change your embeddings?
Not directly. Text embeddings are computed from your visible content, and structured data is a separate signal serving a different layer of the system. Schema markup for AI still earns its keep for entity disambiguation and rich results, just not by moving your vectors.
Do embeddings go stale?
The vector embeddings themselves do not decay, but they are snapshots: when you rewrite a page, nothing changes until the engine recrawls and re-embeds it. Freshness in AI search comes from the retrieval layer picking up current content, which is one more reason crawl access matters more than any optimization trick.
Where This Leaves You
You now know more about retrieval mechanics than much of what gets sold as "AI optimization" assumes you ever will.
The part you cannot control, which production model scores your content and how, is exactly the part to stop paying for. The lever you do control is the writing itself, and the per-passage citability work that makes each section retrievable on its own.
What you can verify is the outcome. geotoolbox exists for that half of the problem: GEO Scan runs your prompts across up to eight AI engines and shows which pages get cited and who beats you, while Content Analyzer grades a specific URL's citability and live-checks which engines cite it. Citations are noisy run to run, engines answer differently each time, so treat any single check as one sample and watch the trend. It is still the right thing to measure: observable, tied to the outcome you want, and unlike a vector score, checkable against reality.
Sources
- Vector embeddings guide - OpenAI API documentation -
developers.openai.com/api/docs/guides/embeddings - File search tool - OpenAI API documentation -
developers.openai.com/api/docs/guides/tools-file-search - The Illustrated Word2vec - Jay Alammar, 2019 -
jalammar.github.io/illustrated-word2vec - BERT: Pre-training of Deep Bidirectional Transformers - Devlin et al., 2018 -
arxiv.org/abs/1810.04805 - Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings - Bolukbasi et al., 2016 -
arxiv.org/abs/1607.06520 - Hybrid search overview, Azure AI Search - Microsoft Learn -
learn.microsoft.com/en-us/azure/search/hybrid-search-overview - AI features and your website - Google Search Central -
developers.google.com/search/docs/fundamentals/ai-optimization-guide - How to Identify Semantically Similar Pages & Outliers - Screaming Frog -
screamingfrog.co.uk/seo-spider/tutorials/how-to-identify-semantically-similar-pages-outliers - Content Structure for AI Search - Chris Green, 2025 -
chris-green.net/post/content-structure-for-ai-search - SEO Use Cases for Vectorizing the Web - Mike King, iPullRank, 2024 -
ipullrank.com/vector-embeddings-is-all-you-need