RAG, short for retrieval-augmented generation, is the technique that lets an AI model look things up before it answers instead of relying only on memory. It is also the machinery behind AI search. When ChatGPT, Perplexity, or a Google AI Overview answers a question and cites a few pages, retrieval-augmented generation is why those pages got pulled in.
Most explainers cover RAG for the people building it. This one is for the people on the other end of it: anyone who publishes content and wants to understand why some pages get retrieved and cited while others never do.
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a technique that lets a large language model look information up at answer time instead of relying only on what it memorized during training. The RAG system retrieves relevant documents; the model then reads the supplied context and writes an answer grounded in it.
The cleanest way to picture it is an open-book exam. A plain language model takes a closed-book exam: it answers from memory, and when memory fails it guesses confidently. RAG hands the same model the textbook and lets it check the relevant page before answering. The knowledge it uses no longer has to be baked into its weights. It can be pulled from a source the moment the question is asked.
That open-book step is also where your content enters the picture. When the model goes looking for a page to ground its answer, it is running a retrieval contest, and your page is either in the running or it isn't. You have almost certainly seen the output already: an AI answer with a handful of sources linked underneath is retrieval-augmented generation in action.
The name describes the sequence exactly: retrieve the relevant documents, augment the prompt with them, then generate the answer. Keep those three words in order and the rest of RAG follows from them.
How RAG Works: Retrieve, Augment, Generate
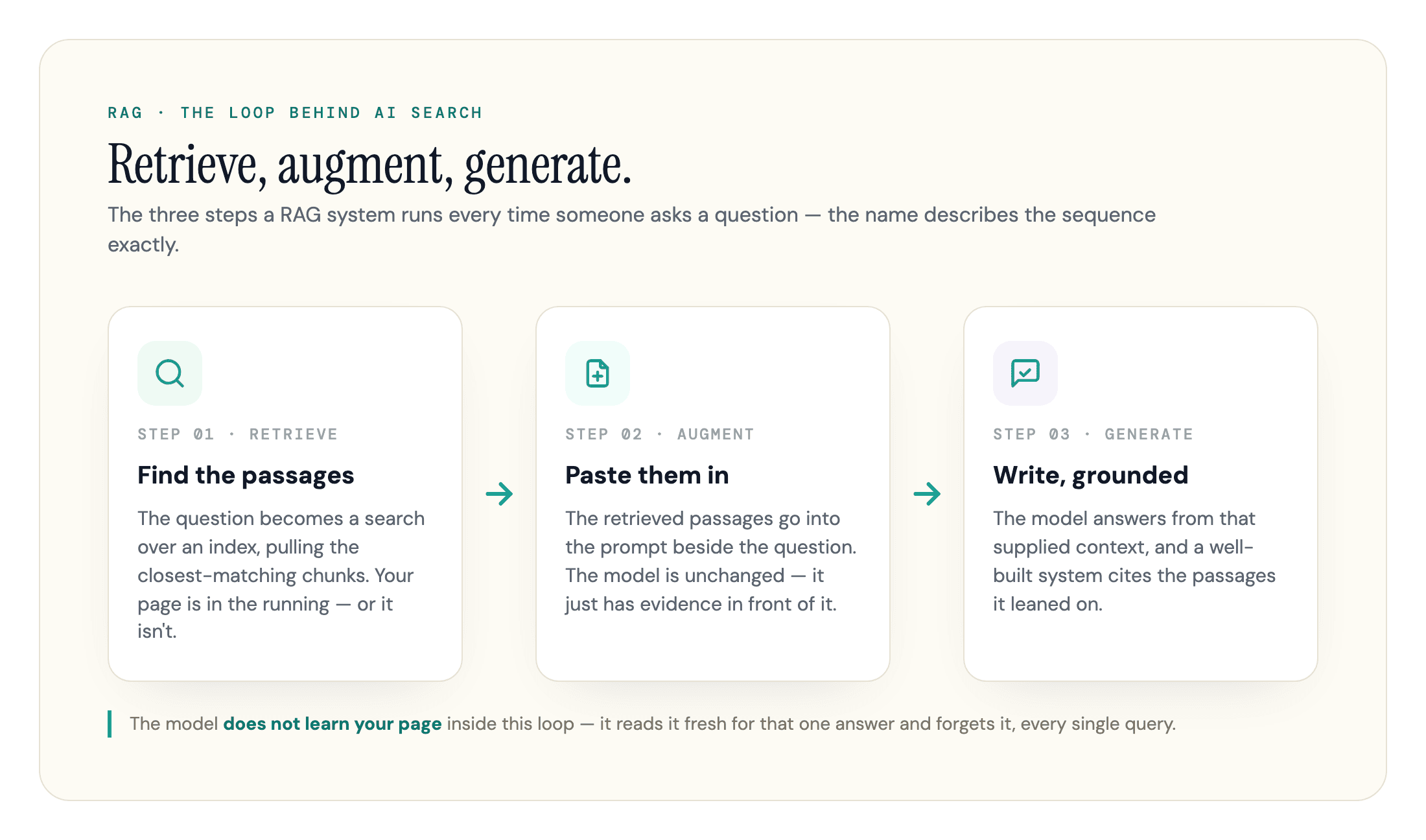
A RAG system runs three steps every time someone asks a question.
Retrieve. The system turns the user's question into a search and pulls the most relevant passages from a knowledge base. That knowledge base is usually a set of documents that have been split into chunks and converted into vector embeddings, numerical representations that let software compare meaning rather than match exact words. An embedding model converts the user query into a vector too, and the retriever finds the passages whose vectors sit closest to it. This is semantic search, often combined with old-fashioned keyword matching for the terms that have to be exact.
Augment. The retrieved passages get pasted into the prompt alongside the original question. The model now sees the user's words plus a few paragraphs of supporting evidence it did not have a second ago. Nothing about the model has changed. It just has more context in front of it for this one request.
Generate. The model writes its answer using that supplied context, and a well-built system asks it to cite which passages it leaned on.
Here is the part most explainers skip, and the part that matters most if you publish content. Inside the RAG loop, the model does not learn your page. It reads it fresh, for that one answer, and forgets it the moment the response is done. Public pages can still get absorbed into a model's weights during training, but that is slow, opaque, and not something you control or can update. Retrieval is. Your content gets fetched, used, and dropped, every single query, which is why being structured, current, and easy to retrieve matters more than being famous enough for the model to "know" you.
The vocabulary trips people up here. A vector database is the common way to store those embeddings for fast retrieval, but it is an implementation detail, not part of the definition. RAG is the broad idea of pairing information retrieval with generation, grounding the answer in retrieved documents. The plumbing underneath can vary.
Where RAG Came From
The term comes from a 2020 paper, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, led by Patrick Lewis with a team of machine learning researchers from Facebook AI Research (now Meta AI), University College London, and NYU. As of July 2026, Google Scholar shows more than 24,000 citations, and it is the reference point everyone else builds on.
The paper's framing is still the most useful one. It describes combining parametric memory, the knowledge stored in a model's trained weights, with non-parametric memory, a searchable index the model can consult at inference time. In the original work that index was a dense vector representation of Wikipedia, reached through a neural retriever. Swap Wikipedia for "the live web" and you have a fair sketch of how AI search engines work today.
Lewis has even said he regrets the clunky acronym, noting the team "would have put more thought into the name had we known our work would become so widespread." It did.
Why RAG Exists: What It Fixes (and What It Doesn't)
A standalone language model has predictable weak spots, and RAG was built to patch them.
It has a knowledge cutoff. Training data is frozen at a point in time, so the model gets steadily more out of date until someone retrains it. RAG sidesteps this by fetching current information when the question is asked. It also has no access to private or proprietary data, the internal documents and recent pages that were never in its training set. RAG connects that external knowledge in without retraining. And because retrieval is cheap compared to fine-tuning a model on new data, it is the cost-effective way to keep answers current.
The headline benefit is grounding. By anchoring answers in retrieved sources, RAG reduces hallucinations, the confident, made-up answers models produce when they are working from memory alone. It also makes answers checkable, because the system can cite the passages it used.
Now the honest part, because this is the single most oversold claim in the category: RAG reduces hallucinations, it does not eliminate them. The model can still misread a correct source, stitch together conflicting passages, or write something unsupported when retrieval comes back thin. Retrieval quality sets a hard ceiling on the whole system: a model cannot ground an answer in a passage the retriever never found.
The evidence is blunt. A Stanford study, Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools, tested commercial legal-research tools that are themselves RAG systems built on curated, authoritative law libraries. It found Lexis+ AI hallucinated on more than 17% of queries and Westlaw's tool on roughly a third, despite marketing that implied none at all. If purpose-built RAG over a clean legal corpus still misses that often, treat any "hallucination-free" promise with suspicion. RAG is a strong mitigation, and that is exactly where its value sits. For more on why this happens, see this breakdown of AI hallucinations.
RAG vs Fine-Tuning: The "Train ChatGPT on Our Docs" Confusion
When a stakeholder says "let's train ChatGPT on our website," they almost always mean RAG, not training. The two get blended constantly, and picking the wrong one is expensive.
Fine-tuning changes the model itself. You run additional training so new patterns get written into its weights. After that the knowledge is internal, there is no lookup step, and updating it means training again. Fine-tuning is the right tool for teaching a model a style, a format, or a behavior.
RAG leaves the model untouched and gives it documents to read at answer time. Knowledge lives in a separate index you can update whenever you want, and the model cites what it pulled. RAG is the right tool for facts that change or that the model was never trained on.
| Question | RAG | Fine-tuning |
|---|---|---|
| What changes? | An external index of documents | The model's own weights |
| When is knowledge added? | At answer time, per query | During a training run, up front |
| Best for | Fresh or proprietary facts | Style, tone, format, behavior |
| Updating it | Edit the index, no retraining | Retrain or re-tune the model |
| Can it cite sources? | Yes | Not by itself / not reliably grounded |
They are not rivals. Production systems often fine-tune for behavior and use RAG for current facts. The original authors even described their method as "a general-purpose fine-tuning recipe" for building RAG models. The practical rule: if the problem is "the model does not know this fact," reach for RAG. If the problem is "the model does not answer in the way we need," reach for fine-tuning.
For publishers, the distinction matters for one reason in particular: the AI engines that might cite you are running RAG, not fine-tuning on your site. Which leads to the part that actually affects your traffic.
RAG Is How AI Search Actually Works
The RAG systems most people actually interact with are the AI search engines you are already trying to show up in, and that is the connection the vendor explainers leave out. They describe RAG as enterprise plumbing: a support chatbot answering over a company's internal data, internal knowledge search, a research assistant reading proprietary files. Those use cases are real, but they are the smaller story.
When ChatGPT browses the web to answer a question, it retrieves web information through ChatGPT search, which OpenAI says uses third-party search providers, partner-provided content, and its search crawling systems. Perplexity typically retrieves and cites sources. Google's AI Overviews draw on Google's Search index and ranking/quality systems, then synthesize selected sources. Different engines, same three steps: retrieve, augment, generate. This is just how AI search works under the hood.
ChatGPT itself shows how the pieces fit. The base model is a language model, but its search and browsing mode wraps that model in a RAG loop, retrieving live pages before it answers. The model is the generator; the product around it is the RAG system.
That reframing changes what "getting cited" means. If AI search is RAG, then getting cited starts with getting retrieved by a RAG pipeline. Retrieval is the qualifying round: the model still chooses which of the retrieved sources to cite, but a page that is never retrieved cannot be cited at all. There is no list of ten blue links to scroll, just one synthesized answer with a few sources. Retrieval is the contest most pages were never written to enter.
How to Be the Page That Gets Retrieved
If you want your pages pulled into AI answers, you have to make them easy to retrieve. This is where RAG stops being trivia and turns into a content strategy, and a few rules follow directly from how the pipeline works.
Passages get retrieved, not pages. A RAG system splits documents into chunks and retrieves the chunk that best matches the query, not your whole article. So each section has to make sense on its own. Put the answer to a question directly under a clear, question-style heading, in the first sentence or two, before the context and caveats.
In our experience auditing pages for AI visibility, this is the most common fixable problem: the answer exists, but it is buried three sentences into a paragraph, and the chunk that gets retrieved is the lead-in, not the payload. Write each section so a reader who lands on it cold still gets the answer. That is the same instinct behind good content chunking, with one caveat: this means writing self-contained sections for readers, not chopping pages into artificial fragments for machines, a distinction we come back to below.
You cannot be retrieved if you cannot be reached. Retrieval runs over an index, and you only enter the index if the engine's crawler is allowed to fetch you. Check that you are not blocking AI crawlers you actually want citing you. Reachability is the floor; everything else is wasted if the page never gets fetched.
Write with unambiguous clarity. Models misread sources that are vague or rely on outside context. State claims plainly and self-containedly so a retrieved snippet cannot be misinterpreted.
Freshness helps, with a caveat. Recency is one of the few signals that correlates with getting cited, since the entire point of retrieval is to beat a model's stale memory. Genuine updates, not date-bumping, are worth making. Just treat freshness as a correlation, not a guaranteed lever.
| What to do | Why it helps retrieval |
|---|---|
| Answer-first sections under clear headings | The retrieved chunk contains the answer, not the wind-up |
| Self-contained paragraphs (one idea each) | A chunk still makes sense pulled out of context |
| Allow the AI crawlers you want citing you | You can only be retrieved if you are in the index |
| Plain, specific, unambiguous claims | Lowers the chance a passage gets misread |
| Keep pages genuinely current | Recency correlates with being pulled into answers |
Ranking well and getting cited are not the same job. Ranking can get a page considered, but retrieval decides whether a passage of yours actually gets quoted, so a page can sit at the top of Google and still never appear in an AI answer.
And no, this is not just SEO with a new logo, though it is closer than the hype suggests. Google itself says its systems can read long, multi-topic pages and extract the relevant passage without you chopping content into artificial fragments, and that the fundamentals of GEO and AEO are still SEO. The honest summary: the same fundamentals (topical depth, authority, clarity), plus a real shift in the unit of retrieval from the page to the passage. If you want the full playbook, we cover it in how to optimize for AI search and writing pages LLMs cite.
Is RAG Dead? Agentic RAG and the Long-Context Debate
Neither huge context windows nor the shift toward AI agents kills retrieval, whatever the "RAG is dead" headlines say. Those are the two reasons usually given: models that can now swallow a whole document set in a single prompt, and more autonomous agents doing the work.
The slogan is really about naive RAG, the simplest version that retrieves once and generates once. That basic pipeline is often not enough for multi-step work, and the industry is moving toward agentic RAG, where an agent decides when to retrieve, reformulates the query, retrieves again, and checks what it got back before answering. That is more retrieval with better judgment around it, not less.
Long-context models are a genuine alternative for some jobs, but pasting everything into the prompt is slower and more expensive than retrieving the few passages that matter, and it does not scale to the open web. So retrieval stays central.
For anyone who publishes content, the practical takeaway does not change. AI search engines still retrieve before they answer. Whether the system is naive or agentic, it has to find your page to cite your page. Being retrievable is still the price of admission.
Frequently Asked Questions
Is ChatGPT a RAG model?
The underlying model is not, but ChatGPT's search and browsing mode is. When ChatGPT looks something up before answering, it retrieves live web pages, adds them to the prompt, and generates a grounded reply. That retrieve-augment-generate loop is RAG, with the model acting as the generator inside it.
Does RAG stop hallucinations?
It reduces them, it does not stop them. Grounding answers in retrieved sources lowers the rate of made-up content, but the model can still misread a source or fill gaps when retrieval comes back weak. A Stanford study found commercial legal RAG tools still hallucinated on 17% to 33% of queries, so treat any "hallucination-free" claim with caution.
What is the difference between RAG and a vector database?
RAG is the overall technique of grounding a model's answer in retrieved documents. A vector database is one component some RAG systems use to store embeddings and run fast similarity search. You can build RAG without one, using keyword search or a knowledge graph instead, so the vector database is a common piece of plumbing, not a requirement.
What are the types or "levels" of RAG?
People usually describe a progression: naive RAG (retrieve once, generate once), advanced RAG (better chunking, reranking, and hybrid search to improve what gets retrieved), and agentic RAG (an agent decides when and what to retrieve and can iterate). They are points on a spectrum, not rigid categories. A separate, complementary idea skips retrieval for a small set of curated facts and hands the agent a structured knowledge file directly, which is the pitch behind OKF vs RAG.
Do I need to build a RAG system to benefit from AI search?
No. Most publishers are on the receiving end of someone else's RAG, not building their own. Your job is to make your existing content easy to retrieve and cite, not to stand up a pipeline.
You Don't Get Into the Model. You Get Retrieved.
So the practical work is short, and it is ongoing: keep pages reachable, write sections that stand alone as clean answers, stay current, and give each one a direct answer worth quoting. Do that and you are optimizing for the retrieval step every AI engine runs, instead of chasing a ranking that may never turn into a citation.
The first thing to check is whether AI engines can even reach and read your pages, because nothing else matters if they can't. That is exactly what our AI Readiness check looks at, and from there you can measure how often you're actually getting cited across the engines that run on retrieval.
Sources
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks - Lewis et al., 2020 (NeurIPS 2020) -
arxiv.org/abs/2005.11401 - What Is Retrieval-Augmented Generation, aka RAG? - NVIDIA, 2023 (updated 2025) -
blogs.nvidia.com/blog/what-is-retrieval-augmented-generation - Retrieval-augmented generation - Wikipedia -
en.wikipedia.org/wiki/Retrieval-augmented_generation - Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools - Magesh et al., Stanford RegLab & HAI, 2024 -
reglab.stanford.edu/publications/hallucination-free-assessing-the-reliability-of-leading-ai-legal-research-tools - Guide to Optimizing for Generative AI Features on Google Search - Google Search Central -
developers.google.com/search/docs/fundamentals/ai-optimization-guide