Schema markup for AI search is the most over-promised tactic in generative engine optimization right now. Vendors pitch it as a citation multiplier; skeptics call it dead code that models never read. Both are wrong in instructive ways. Two engines are on record that structured data helps them understand content, the only intervention study so far found that adding it barely moved citations, and an implementation detail as small as how you inject the markup decides which AI crawlers ever see it. This guide sorts the confirmed from the claimed, and shows how to verify your markup even arrives.
What Schema Markup Actually Does in AI Search
Schema markup is JSON-LD code that labels what your page contains: this is an article, written by this person, who works for this organization, about this topic. Search engines have read it for years to power rich results. The new question is whether AI search reads it too, and the honest answer is: some engines do, some almost certainly do not, and nobody's markup turns a weak page into a cited one.
The most useful way to think about it comes down to a split. The quality and authority of your content decide whether you are worth citing. Structured data decides, at most, how easy you are to cite: it removes guesswork about who you are, what the page covers, and which facts belong to which entity.
That second job is real but narrow. AI systems that retrieve your page have to work out whether "Mercury" means the planet, the element, or your agency's brand name. Markup that ties the page to a defined organization, author, and topic shortens that inference. It is plumbing for machine understanding: the same job it has always done in classic SEO, carried over into generative engine optimization.
What schema does not do is act as an AI ranking lever. No engine has ever said "add markup, get cited," and the newest data points the other way. The citation-hack version of the pitch is the one part of this the evidence does not support.
Does AI Use Schema Markup? Engine by Engine
Two platforms have said yes on the record for their AI surfaces broadly, and one more is on record for shopping only. For citations everywhere else, silence is not a yes.
| Engine | Uses schema? | The evidence |
|---|---|---|
| Google AI Overviews / AI Mode | Reads it, doesn't require it | Google's generative AI optimization guide (updated June 2026): structured data "isn't required for generative AI search," but keep using it for rich-result eligibility and the features that depend on it. |
| Microsoft Bing Copilot | Confirmed | Fabrice Canel, principal product manager at Bing, said on stage at SMX Munich (March 2025) that schema markup helps Microsoft's LLMs understand content. |
| ChatGPT | Citations: no confirmation. Shopping: yes | OpenAI has never said its search citations use schema, but its shopping surface documents structured product metadata and a merchant product feed spec. ChatGPT search uses third-party providers and partner content; OpenAI does not publicly name Bing here. High overlap with Bing's index is a dated inference, not a platform confirmation. |
| Gemini | No statement | Google's structured-data statements cover Search's AI features, not the Gemini app. Nothing published either way. |
| Perplexity | No confirmation | No public statement on schema anywhere in its answer pipeline. |
| Claude | No confirmation | Anthropic has published nothing on structured data in its search or citation pipeline. |
One more official line worth keeping verbatim, because it kills a whole category of snake oil. Per the same Google guide: "there's no special schema.org markup you need to add" for AI features, and Google's AI features documentation adds that no AI-specific files or markup exist at all. Eligibility for an AI Overview citation is the same as for a snippet: be indexed, be crawlable. If a vendor pitches you an "AI schema type," the markup does not exist. The same guide's ignore list also covers "chunking" content, a sibling myth we examine separately.
So the platform answer to "does AI use schema markup" is: Google and Bing, yes, as an understanding signal. Everyone else, unknown, and unknowable until they say so or someone tests it properly. Which someone now has.
What the Evidence Says (and How Strong It Is)
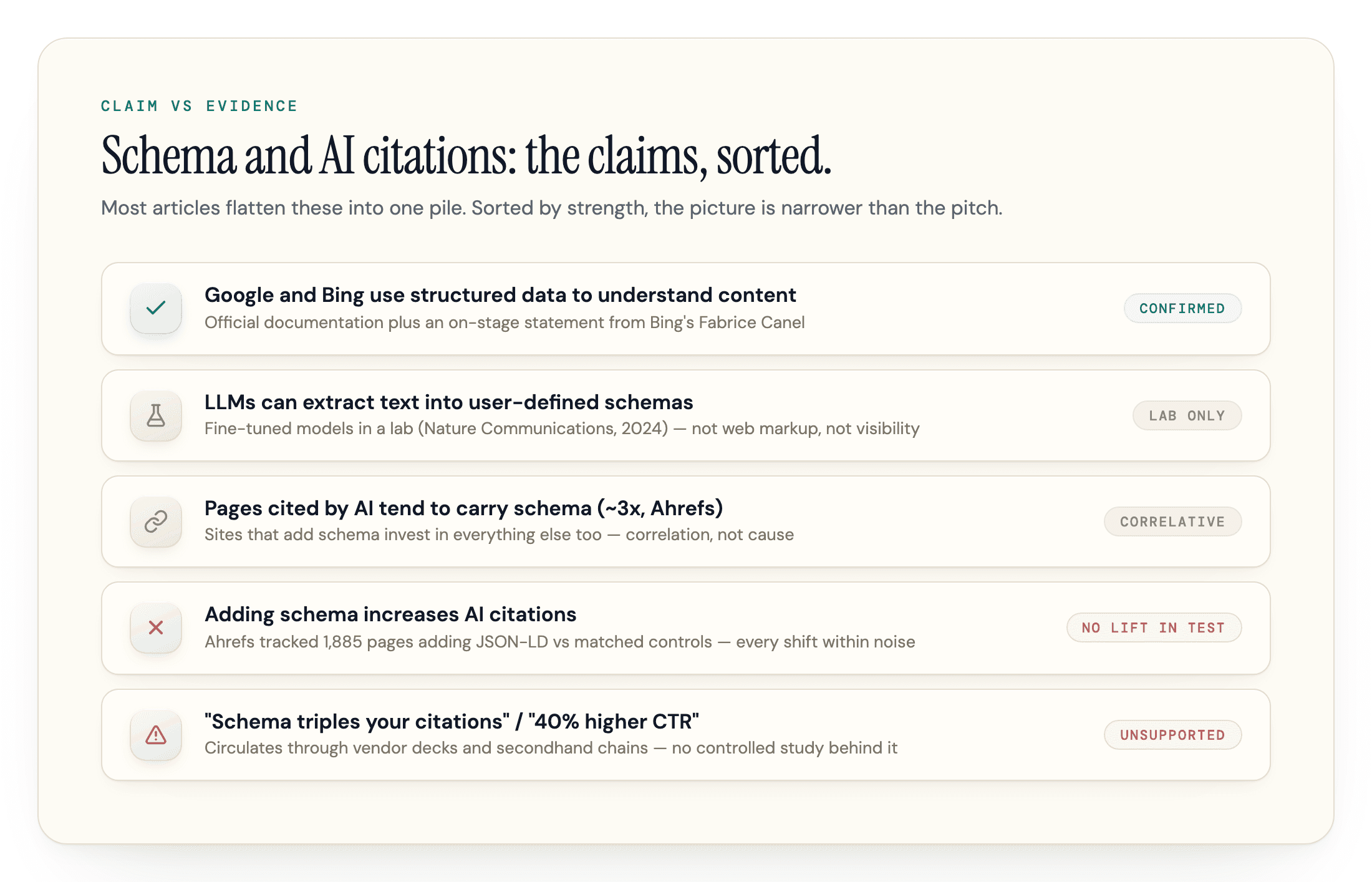
Claims about schema and AI visibility come in wildly different strengths, and most articles flatten them into one pile. Here is the same pile, sorted.
| Claim | Verdict | Basis |
|---|---|---|
| Google and Bing use structured data to understand content | Confirmed | Official documentation and an on-stage statement from Bing's Fabrice Canel |
| LLMs can extract text into user-defined structured schemas | Demonstrated in the lab | A Nature Communications study (February 2024) showed fine-tuned LLMs reliably extracting scientific text into user-defined schemas. Scope: trained models in a lab, not web markup, not visibility. |
| Pages cited by AI tend to have schema | Correlative only | Across 6 million URLs, Ahrefs found AI-cited pages were almost 3x more likely to carry JSON-LD, which is where the "3x" stat in vendor decks comes from. Sites that add schema also invest in everything else; the correlation is real, the causation is what the test below checks. |
| Adding schema increases AI citations | No lift in the only intervention test | Ahrefs tracked 1,885 pages that added JSON-LD against roughly 4,000 matched controls: Google AI Overviews -4.6%, AI Mode +2.4%, ChatGPT +2.2%, everything within noise except the small AIO decline. The study's own scope caveats: pages already cited 100+ times, 30-day windows, all schema types pooled. |
| "Schema triples your citations" / "40% higher CTR" | Claimed, unsupported | These numbers circulate through vendor decks and secondhand citation chains. None traces to a controlled study. Treat any precise multiplier with suspicion. |
The Ahrefs result deserves careful reading rather than a victory lap in either direction. It is the only intervention test we know of, and it found nothing for pages that were already getting cited. What it cannot rule out, by its own design, is a longer-horizon or entity-establishment effect for unknown brands, which is the population schema advocates care most about. The fair summary: the burden of proof now sits with anyone claiming a citation lift.
There is also a technical riddle the hype skips over: do the models even see your markup? The one public test we know of says yes, but not in the way schema fans hope. Mark Williams-Cook planted a fake company's address only inside deliberately invalid JSON-LD, and both ChatGPT and Perplexity served it back. The models had tokenized the script block as plain page text: no parsing, no validation, no credit for structure. So "tokenization strips your markup" is false, and so is "the AI parses your graph." In Williams-Cook's test, the text inside invalid JSON-LD reached ChatGPT and Perplexity through a page fetch; that test doesn't prove all systems ignore schema structure, but it does show the text pathway exists. Where structure plausibly pays is upstream, in the Google and Bing pipelines that are confirmed to parse it. Which raises the question almost nobody asks: does your markup survive the crawl at all?
Does Your Schema Even Reach the Model? The Crawler Layer
Before any debate about whether an engine uses your markup, there is a blunter question: did the engine's crawler receive it? This is where schema implementations quietly fail, and no validator will tell you.
Here is the mechanical reality. Many AI crawlers are raw-HTML-first or have been observed missing client-rendered content (e.g., the Vercel/MERJ crawler study); unless you have bot-specific evidence, treat JavaScript-injected schema as at-risk and verify with the exact crawler/user agent. That cuts in two directions:
- JSON-LD hard-coded in your HTML travels fine. A script tag in the source is just text in the document those bots download. Whether their pipelines parse it is the open question from the table above, but at least it arrived.
- JSON-LD injected by JavaScript may not arrive for crawlers that do not render the page. If your markup is added by Google Tag Manager, a consent management platform (CMP), or any client-side script, the bots that skip rendering download a page with no schema in it at all. Google can process JavaScript when it is not blocked, and Bing can process some JavaScript, but server-side JSON-LD is still safer, and that is exactly why this failure hides: the Rich Results Test shows green while the entire unconfirmed column above receives nothing. Per the Williams-Cook test, text reaching the model is the one pathway proven to work at answer time, and it is the pathway tag-manager injection forfeits.
In our experience analyzing pages for AI visibility, this is one of the most common surprises we find: markup that validates perfectly in Google's tools but is absent from the HTML an AI crawler actually receives, because it ships through a tag manager.
The 60-second check: open your page with view-source (not inspect, which shows the rendered DOM) or run curl on the URL, and search for application/ld+json. If your markup is only in the rendered version, move it server-side. The same JavaScript dependency that hides schema usually hides content too, which is the deeper problem covered in our guide to agent-ready websites.
Check the access layer first
Schema is irrelevant if the bots cannot fetch the page at all. The free AI Crawler Checker shows which of 34 AI crawlers your robots.txt allows or blocks, with the exact line to fix.
The Schema Types Worth Implementing for AI
Schema.org defines hundreds of types. For AI search, a short stack covers nearly all the value, and everything past it is diminishing returns.
Organization, Sitewide
This is your brand's identity record: name, logo, URL, and most importantly sameAs links to your LinkedIn, Wikipedia, Crunchbase, and other verified profiles. By the rubric above, sameAs is a mechanism argument rather than an engine confirmation, but it is likely the highest-value field here: it lets a system collapse scattered mentions of your brand into one entity instead of several uncertain ones. A minimal version:
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://example.com/#organization",
"name": "Example Co",
"url": "https://example.com",
"logo": "https://example.com/logo.png",
"sameAs": [
"https://www.linkedin.com/company/example-co",
"https://x.com/exampleco"
]
}Article Plus Person, on Every Post
Use Article (or BlogPosting), with headline, author, dates published and modified, and publisher. This ties content to a named human and a brand, the attribution layer engines lean on for trust signals like E-E-A-T. We ship exactly this on the page you are reading, plus BreadcrumbList and FAQPage, so the code examples here are the markup we run ourselves.
FAQPage, with Honest Expectations
Google restricted FAQ rich results to government and health sites in August 2023, then retired the feature entirely in May 2026, so anyone promising FAQ dropdowns in the SERP is years out of date. Google's only comfort on leftover markup is neutral: unused structured data causes no problems, it just has no visible effect. The real case for keeping FAQPage is the extraction logic above: a clean question-answer block is the easiest format for AI systems to lift, and the Williams-Cook test shows the text inside your markup does reach the models. Add it for genuine FAQ content, never for the SERP feature. HowTo markup sits in the same bucket: its rich result died in 2023, and the structured steps stay cheap to keep where content is genuinely procedural.
Product and Review, Only Where Real
If you sell, structured price, availability, and rating data gives an AI shopping answer your numbers to quote instead of a reseller's; OpenAI's merchant feed spec and Google's Shopping surfaces both consume structured product data, which makes commerce the one corner of AI search where markup is closest to table stakes. If you do not, skip these entirely; marking up reviews that do not exist visibly on the page is the classic path to a manual action.
Past that stack, niche types earn their keep only where the content genuinely exists: VideoObject with a transcript if video matters to you, SoftwareApplication if you sell software, LocalBusiness if customers walk through a door. Notice what is absent from all of this: nothing AI-specific, because per Google, no such type exists.
How to Implement It: JSON-LD, @id, and the Entity Graph
Use JSON-LD over microdata or RDFa. Google recommends it explicitly, it lives in one script block instead of being threaded through your HTML attributes, and it is the format every generator and plugin outputs by default.
Where the code physically goes, by stack: on a hand-built or framework site, a <script type="application/ld+json"> block in the <head> or body, rendered server-side; on WordPress, Yoast and Rank Math emit Article and Organization graphs from their settings screens, and a header-snippet plugin covers anything custom; on Shopify and Wix, themes and apps inject it at the template level. The one place not to put it is a tag manager, for the crawler reasons above.
The implementation pattern that actually serves AI is connecting your blocks instead of scattering them. Give each entity a stable @id and reference it across the site, so your Organization, your authors, and your articles form one graph rather than disconnected fragments:
{
"@context": "https://schema.org",
"@graph": [
{ "@id": "https://example.com/#organization", "@type": "Organization", "name": "Example Co" },
{ "@id": "https://example.com/#jane-doe", "@type": "Person", "name": "Jane Doe",
"worksFor": { "@id": "https://example.com/#organization" } },
{ "@type": "Article", "headline": "Schema Markup for AI Search",
"author": { "@id": "https://example.com/#jane-doe" },
"publisher": { "@id": "https://example.com/#organization" } }
]
}Same entities on every page, same @id values, no guessing required about who wrote what for whom. How engines use entity signals like these to build their picture of your brand is its own topic, covered in our guide to entity SEO and the knowledge graph; this article stays on the markup mechanics.
Three implementation rules prevent most of the damage we see:
- Audit what your plugins already emit before adding more. Yoast, Rank Math, and theme builders each inject their own graphs, and stacking a generator on top produces duplicate or contradicting blocks. One source of truth per entity.
- Markup must mirror visible content. Schema describing ratings, FAQs, or authors that a human cannot see on the page violates Google's guidelines and is manipulative noise to AI systems that cross-check markup against visible text.
- Validate, then verify delivery. Run the Rich Results Test and the Schema.org validator, then do the view-source check from the crawler section. Validation proves your code parses; only the raw HTML proves the bots receive it.
How to Tell If Schema Is Doing Anything for You
Measure schema like infrastructure, not like a campaign. The Ahrefs numbers above are the expectation-setter: do not anticipate a citation jump in the weeks after deployment, and be skeptical of anyone who promises one.
What is worth watching:
- Search Console's enhancement reports. Errors and valid-item counts tell you whether Google parses your markup at all. This is table stakes, not victory.
- Your citation picture over time. Whether AI engines actually cite you for the prompts your buyers ask is the metric schema is supposed to serve. Run your prompt set on a schedule and watch the trend, not a single snapshot; the manual version of that workflow is in our guide to tracking AI visibility, and geotoolbox automates it.
- One caveat on before/after reads. If citations move after you ship schema, remember you probably shipped other improvements too. The cleanest reading of all current data is that content and authority move citations; schema rides along.
Schema Is Infrastructure, Not a Citation Hack
The verdict fits in three sentences. Schema markup is confirmed plumbing for Google and Bing's AI surfaces, an unconfirmed maybe almost everywhere else, and unsupported by any test as a citation mover on its own. It is also cheap and stable: implement it once, then re-verify on a schedule instead of tuning it weekly. So ship the short stack, hard-coded in your HTML, verified in the raw source, and spend the effort you saved on the content and authority that decide whether you are worth citing in the first place.
If you want the machine's-eye view of a specific page, the Content Analyzer grades it the way this article thinks. It checks whether your JSON-LD is present, well-formed, and type-correct, diffs what renders with and without JavaScript, and scores how citable the content itself is: the plumbing and the substance in one pass.
Frequently Asked Questions
Does schema markup work on JavaScript frameworks like React or Next.js?
Yes, if it renders server-side. Next.js, Nuxt, and similar frameworks using server-side rendering or static generation put the JSON-LD in the HTML response, where every crawler receives it. A purely client-side app injects it after load, which only rendering bots ever execute. On a client-only stack, emit the markup from the server layer or pre-render the pages that matter.
Is the default schema from Yoast or Rank Math enough?
For the basics, usually: both emit a connected Article, Organization, and BreadcrumbList graph out of the box. Check two gaps before trusting it. The sameAs array ships empty until you supply your profile URLs in settings, and double-emission happens whenever a theme or second plugin also injects markup. Validating one representative page exposes both in about a minute.
What is the difference between the Rich Results Test and the Schema.org validator?
The Rich Results Test checks only whether markup qualifies for Google's rich-result features, so it ignores valid schema Google has no feature for. FAQ rich results stopped appearing in Google Search on May 7, 2026; Google is removing the FAQ search-appearance filter, the rich-results report, and Rich Results Test support in June 2026, and Search Console API support in August 2026. FAQPage markup stays valid (it won't cause problems) but no longer produces visible Google results. The Schema.org validator checks syntax and vocabulary for every type. Use the validator for correctness, and the Rich Results Test only when chasing a specific Google feature.
Is schema markup the same job as llms.txt?
Different layers entirely. Schema annotates entities and facts inside a page; llms.txt is a site-level index file proposed as a curated map for AI agents. Neither has confirmed citation impact, but schema at least has confirmed readers. If you want both layers checked, start with the page-level markup.
Should I add schema to every page or only key pages?
Ship the template-level types sitewide, since they cost nothing per page: Organization once, Article and BreadcrumbList on every post automatically. Reserve hand-built markup, such as Product details and genuine FAQ blocks, for the pages that earn money or answer real questions. Marking up thin or duplicate pages adds bytes, not signals.
Sources
- Google - Optimizing your website for generative AI features on Google Search (updated June 2026) -
developers.google.com/search/docs/fundamentals/ai-optimization-guide - Google - AI Features and Your Website -
developers.google.com/search/docs/appearance/ai-features - Google - Introduction to structured data markup -
developers.google.com/search/docs/appearance/structured-data/intro-structured-data - Ahrefs - We Tracked 1,885 Pages Adding Schema. AI Citations Barely Moved. (May 2026) -
ahrefs.com/blog/schema-ai-citations - Search Engine Land - Microsoft Bing/Copilot use schema for its LLMs (March 2025) -
searchengineland.com/microsoft-bing-copilot-use-schema-for-its-llms-453455 - Nature Communications - Structured information extraction from scientific text with large language models (February 2024) -
nature.com/articles/s41467-024-45563-x - Google - FAQPage structured data reference -
developers.google.com/search/docs/appearance/structured-data/faqpage - Google - Rich Results Test -
search.google.com/test/rich-results - Google - Changes to HowTo and FAQ rich results (August 2023) -
developers.google.com/search/blog/2023/08/howto-faq-changes - OpenAI - Product feed spec for ChatGPT shopping -
developers.openai.com/commerce/specs - Mark Williams-Cook - Schema, LLMs and the Low Bar for "Evidence" in GEO -
markwilliamscook.substack.com/p/schema-llms-and-the-low-bar-for-evidence