Most ChatGPT vs Perplexity comparisons answer one question: which one should you use day to day. This is not that. If you care about whether your brand shows up when someone asks an AI, the comparison that matters is mechanical. How does each engine find information, which sources does it trust, and how does it decide what to cite?
Perplexity vs ChatGPT looks like a feature fight from the outside. Underneath, they are two different retrieval systems pulling from two largely different pools of sources. If you are still getting your bearings on the products, our explainer on what Perplexity is covers the basics first. That difference is why a page cited by one can be invisible in the other, and why a single AI visibility strategy rarely works for both. The same split runs through Claude vs ChatGPT and Gemini vs ChatGPT, which compare the two largest assistants under the hood.
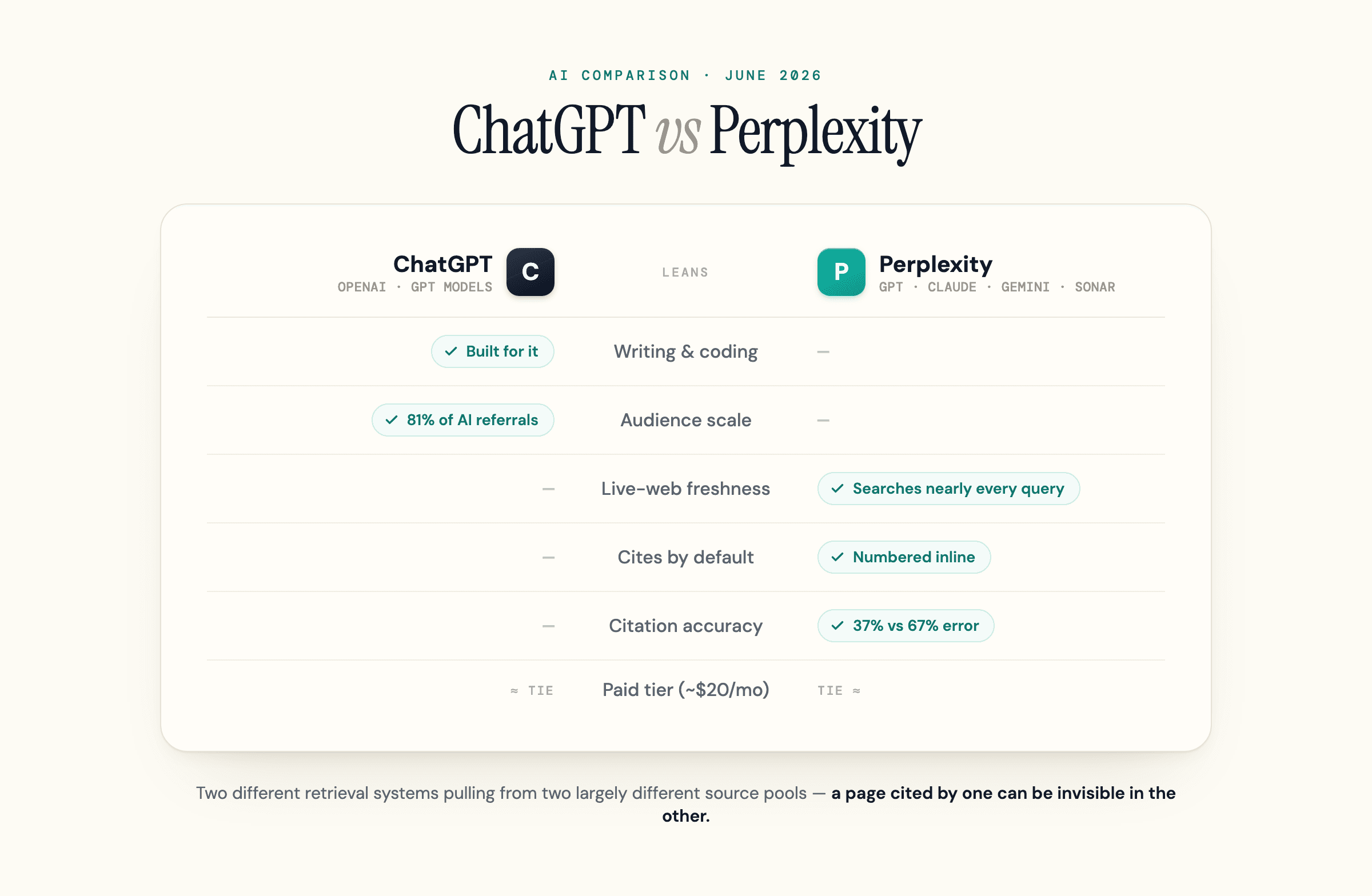
ChatGPT vs Perplexity at a Glance
Perplexity is a search-first answer engine that runs a live web search and cites its sources by default. ChatGPT is a conversation-first assistant that answers from its trained model and cites only when it decides to search. Almost every practical difference follows from that one split.
| Dimension | ChatGPT | Perplexity |
|---|---|---|
| Product type | General-purpose conversational assistant | Answer engine (search-first) |
| Default sourcing | Trained model first; searches the web when it judges the question needs it | Live web search on nearly every query |
| How it cites | Links and a sources panel when it searches; often no citation in plain chat mode | Numbered inline citations by default |
| Knowledge freshness | Training cutoff that lags the live web unless it searches | Real-time; can cite a page published minutes ago |
| Underlying models | OpenAI GPT models | Routes across GPT, Claude, Gemini, and its own Sonar |
| Paid tier | About $20/mo (Plus), with a higher pro tier | About $20/mo (Pro), with a higher max tier |
| Best at | Writing, coding, long-form reasoning | Research, current events, cited fact-finding |
The paid tiers sit at roughly the same price, so "which is cheaper" is not the real question. The real question is which sources each engine reaches for, and whether yours is one of them.
How Each Engine Actually Retrieves Information
The core difference is when each one looks at the live web. Perplexity runs a search on almost every query and builds the answer from what it just fetched, then footnotes each claim with a numbered source. The retrieval happens first, and the answer is assembled from it. That is what makes Perplexity feel like a search engine that writes paragraphs instead of listing links.
ChatGPT works the other way around. It answers from its trained model first, and only runs a web search when it judges the question needs current information. When it does search, OpenAI says it returns answers with linked sources. When it doesn't, the answer comes from training data that lags the live web, and you get no citation at all. If you want the mechanics of how retrieval works across engines, we cover that in how AI search works.
When ChatGPT Decides to Search
Here is the part that trips people up. The claim that "ChatGPT doesn't cite sources" is only true in one mode. In plain chat, it answers from memory and cites nothing. In its search and deep-research modes, it pulls live pages and shows them. The inconsistency is the catch: with Perplexity you can assume a live fetch, with ChatGPT you cannot, which changes how reliably your content can surface. The deeper version of this, including OAI-SearchBot (the crawler that gates ChatGPT search eligibility — GPTBot is training only, ChatGPT-User is user-triggered fetches), lives in our guide to SEO for ChatGPT.
Who Each Engine Cites (and Why It Matters for You)
The two engines reach for different kinds of sources, and that is the whole game for visibility. In a May 2026 US citation audit of ChatGPT, 5W Public Relations found Wikipedia (13.15%) and Reddit (11.97%) together drive more than a quarter of all citations, while the Wall Street Journal, New York Times, Bloomberg, and Financial Times did not appear in the top 20 at all. ChatGPT leans encyclopedic and community-driven, not toward the business press most brands chase.
Perplexity weights its pool differently. The same research notes that each engine sources its own way, with Perplexity skewing toward LinkedIn, the National Institutes of Health (NIH), and G2. So the place you earn a mention is not one place. It is a Wikipedia entry and a strong Reddit presence for one engine, and LinkedIn, review sites, and professional sources for the other.
Video sits underneath both. Ahrefs' 75,000-brand analysis (Dec 2025, cited by 5W) found YouTube mentions show the strongest correlation with AI visibility (0.737, Spearman) across ChatGPT, AI Mode, and AI Overviews — a signal, not proven cause (Ahrefs itself cautions correlation isn't causation), and note Perplexity wasn't in that dataset. If you want to see where you currently stand, our piece on AI share of voice walks through measuring your slice of the answers. The short version: which sources an engine trusts decides whether your AI citation ever happens.
The Source-Pool Gap: Why Cited by One Isn't Cited by Both
Being cited by ChatGPT does not mean you are cited by Perplexity. This is the most common misconception we see in AI visibility work. Because the two engines build answers from largely different source pools, your presence is engine-specific. A page that anchors a ChatGPT answer can be completely absent from Perplexity on the exact same question.
In our experience running AI visibility scans, the same URL routinely shows up strong in one engine and nowhere in the other, even for identical queries. People read a single ChatGPT result, see their brand, and assume they have "AI visibility." They have visibility in one engine, measured once.
That snapshot problem gets worse because the pools move. The 5W audit recorded the share of ChatGPT responses citing Reddit collapsing from roughly 60% to about 10% in two weeks in September 2025. Citation sets are not stable, so a one-time check in one engine tells you almost nothing about your real coverage. The fix is to measure each engine separately and on a schedule, which is exactly what an AI rank tracker is for.
Why Freshness and Recency Are a Brand Risk
Perplexity's live-search behavior makes fresh content more likely to be considered, and studies have found freshness associated with higher citation frequency; ChatGPT can surface recent content when it searches. Perplexity fetches live for nearly every query, so a page you updated this morning is eligible this afternoon. ChatGPT can use and cite recent pages when it searches, but in plain chat it answers from memory that may be months old, which is where the risk hides.
The risk is stale information served with confidence. If your pricing, product details, or policies changed recently and ChatGPT answers from memory instead of searching, it can describe your brand as it was, not as it is. The reader has no way to tell a memory answer from a fresh one. Your old facts become the AI's current facts.
The volatility from the section above compounds this. When citation sets can swing by 50 points in two weeks, stale or unmaintained content can become less competitive quickly. Keeping the pages that describe your brand current is the baseline for AI visibility. The practical steps for structuring and refreshing content so engines keep reaching for it are in our step-by-step playbook for AI search.
Can You Trust Their Citations?
A citation is not a fact-check, and treating it as one is a mistake. Columbia Journalism Review's Tow Center tested eight AI search engines on 1,600 queries in March 2025; wrong citations came back more than 60% of the time, and Perplexity, the most accurate of the group, still erred on 37%. ChatGPT incorrectly identified 134 of 200 articles in the same study.
So the comforting idea that "Perplexity shows its sources, so it must be accurate" does not hold. Showing a source is not the same as the source supporting the claim. The engines invent headlines, attribute content to the wrong outlet, and link to syndicated copies instead of originals. For ChatGPT specifically, how ChatGPT cites sources breaks down what it shows and why it gets citations wrong. (Note that Ahrefs' prompt-log analysis there measures something different from the 5W figure used here: the rate at which retrieved Reddit URLs get cited, not Reddit's share of all citations, so the two numbers describe different things rather than contradicting each other.)
For a brand, the exposure is direct. An engine can misattribute your content, cite a scraper instead of you, or pin a claim you never made to your name, then repeat it confidently to everyone who asks. That is the same failure mode we cover in why AI gets your brand wrong, and a visible citation does nothing to prevent it.
What This Means for Your Brand: Two Playbooks
Because of that pool gap, you need a per-engine plan rather than one generative engine optimization strategy stretched across both.
| Lever | To get cited in ChatGPT | To get cited in Perplexity |
|---|---|---|
| What it rewards | Entity authority and encyclopedic presence | Freshness and answer-first page structure |
| Sources to earn | Wikipedia, established references, Reddit | Reddit, LinkedIn, review sites (G2), YouTube |
| Crawl access | Allow OAI-SearchBot (blocks you from ChatGPT search); GPTBot is training only | Allow PerplexityBot and stay live-fetchable |
| Content cadence | Steady, authoritative, well-linked | Frequently updated, current |
Each engine has its own full playbook: For the ChatGPT side, including the OpenAI crawlers and what actually gets picked, see SEO for ChatGPT. For the Perplexity side, including PerplexityBot and the Publishers' Program, see how to get cited in Perplexity. A third engine, Claude, adds its own pool again, which only reinforces the point.
What ties the two playbooks together is measurement. You cannot optimize for an engine you are not watching, and the engines disagree, so geotoolbox is built to check reachability and track presence across them rather than trusting a single result.
Crawling, Licensing, and the Agentic Browsers
Who each engine is allowed to cite is shaped by crawl behavior and licensing, not just content quality. OAI-SearchBot builds the index behind ChatGPT search, so blocking it removes you from what ChatGPT search can cite, while GPTBot only controls training. That makes your robots rules a visibility decision, which is why knowing which AI crawlers you allow matters more than most site owners realize.
See what you're blocking
The free AI Crawler Checker shows which of 34 AI crawlers your robots.txt allows or blocks, with the exact line to fix.
Perplexity sits at the center of the messier story. In August 2025, Cloudflare reported that Perplexity used stealth, undeclared crawlers that impersonated a normal browser to fetch pages after its declared bot was blocked, generating millions of requests a day. Cloudflare de-listed Perplexity as a verified bot. Perplexity disputed the finding and said the traffic was misattributed. That dispute is unresolved, and it was not the last. In October 2025, Reddit sued Perplexity and three data-scraping firms in federal court, alleging they harvested Reddit content through Google search results at industrial scale after direct crawling was blocked; Perplexity disputes that claim too. The crawl numbers explain the tension: Cloudflare measured roughly 194 Perplexity crawls for every visitor it referred back as of July 2025, and about 1,100 for OpenAI. Underneath it sits the real fight: publishers want control over who reads their work, and the rules are still being written.
Licensing is the other half. OpenAI has signed content deals with publishers including the Associated Press and News Corp, and Perplexity runs a Publishers' Program that shares revenue when a partner's content is cited. In August 2025, Perplexity announced Comet Plus, a $5-per-month tier that passes 80% of its subscription revenue to participating publishers, seeded with a $42.5 million pool. Both shape which sources an engine can surface. And the next layer is already here: agentic browsers like Perplexity's Comet and ChatGPT's Atlas now act on your site, which makes being agent-ready the new edge of AI visibility.
Which Should You Use?
For research, current events, and anything where you need to see the sources, use Perplexity. For writing, coding, and long-form reasoning, use ChatGPT. Most professionals end up using both, because they are built for different jobs. For a brand, the better question is not which one you use, but which ones your customers use to ask about you.
Stop Guessing Which Engine Sees You
There is no winner here, and the citation sets shift week to week. Picking a favorite chatbot is a personal preference. Knowing where your brand actually shows up is measurable, though any reading, ours included, is a sample of a probabilistic system, so read trends rather than single checks. Most brands have never checked either engine even once.
If you are not even sure AI engines can reach and read your site, the free AI Readiness check from geotoolbox shows whether they can actually reach and read it. That is the first thing to fix, before you worry about which engine cites you, because an engine that cannot read your page cannot cite it in any answer.
Frequently Asked Questions
Does Perplexity cite Reddit more than ChatGPT?
Both lean on Reddit heavily, but they weight their pools differently. Reddit ranks near the top across engines, while Perplexity also skews toward LinkedIn, NIH, and review sites like G2, and ChatGPT leans on Wikipedia.
If my site is cited by ChatGPT, will it show up in Perplexity too?
The reliable overlap is narrow: community and reference sources (Reddit, Wikipedia-class pages) tend to surface in both, while business press, vendor blogs, and niche sites diverge sharply. If you only have budget to earn presence on one source type, the overlap zone is where it pays twice.
Can I trust the citations Perplexity and ChatGPT give me?
Verify before you act: click the citation, find the quoted claim on the page, and check it is the original rather than a syndicated copy. Those three checks catch the bulk of the error modes the audits found, and they take under a minute per citation.
Do I need a different SEO strategy for each engine?
With limited budget, sequence rather than split: run the shared foundation first (reachability, answer-first pages, entity cleanup), because both engines require it. Add the engine-specific layer only for the engine your buyers actually use; check your AI referral traffic before deciding which that is. For scale context, BrightEdge measured ChatGPT at 81.4% of AI referral traffic in Q1 2026, with Gemini at 11.6% and Perplexity at 4.6%.
Why is Perplexity controversial?
The deeper issue than the 2025 crawler dispute and the Reddit scraping lawsuit is the precedent question: whether an AI company may fetch content a publisher has explicitly blocked, on the theory that a user asked for it. How that resolves (in courts and in standards like Web Bot Auth) will shape every engine's behavior, not just Perplexity's.
How much did Jeff Bezos invest in Perplexity?
Bezos backed Perplexity through a $73.6 million round (alongside Nvidia) that valued the company at about $520 million in early 2024. Later rounds have pushed that valuation far higher.
Sources
- Columbia Journalism Review, Tow Center: AI Search Has a Citation Problem -
cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php - 5W Public Relations: Wikipedia and Reddit Now Drive Over 25% of ChatGPT Citations in the US -
prnewswire.com/news-releases/wikipedia-and-reddit-now-drive-over-25-of-chatgpt-citations-in-the-us-new-5w-research-finds--wsj-nyt-and-bloomberg-do-not-appear-in-the-top-20-302768339.html - Cloudflare: Perplexity is using stealth, undeclared crawlers -
blog.cloudflare.com/perplexity-is-using-stealth-undeclared-crawlers-to-evade-website-no-crawl-directives - OpenAI: Introducing ChatGPT search -
openai.com/index/introducing-chatgpt-search - Perplexity: Introducing the Perplexity Publishers' Program -
perplexity.ai/hub/blog/introducing-the-perplexity-publishers-program - Fortune: Jeff Bezos and Nvidia back Perplexity -
fortune.com/2024/03/10/jeff-bezos-perplexity-ai-tech-investment - BrightEdge: Gemini Becomes No. 2 Consumer AI Referral Source in Q1 2026 -
brightedge.com/news/press-releases/brightedge-data-gemini-second-largest-ai-referral-source-q1-2026 - Cloudflare: The crawl-to-click gap -
blog.cloudflare.com/crawlers-click-ai-bots-training - Search Engine Land: Reddit sues Perplexity, SerpApi over scraping -
searchengineland.com/reddit-sues-perplexity-serpapi-scraping-google-463681 - Engadget: Perplexity has cooked up a new way to pay publishers -
engadget.com/ai/perplexity-has-cooked-up-a-new-way-to-pay-publishers-for-their-content-204255019.html