Those little numbered links in a ChatGPT answer are its citations, the web pages the model pulled to build the response. The machinery behind them is stranger than it looks: ChatGPT reads far more than it credits, and the credits it does show are wrong more often than most people assume.
One quick disambiguation first. If you came here to learn how to cite ChatGPT itself in an APA or MLA paper, that is a different question with a short answer in the FAQ. This article is about how ChatGPT cites its sources, which is what matters if you care whether your content is the thing it points to.
What a ChatGPT Citation Actually Is
A ChatGPT citation is a link to a web page the model retrieved to build its answer. When ChatGPT runs a web search, it surfaces those sources two ways: as inline numbered links in the text, and in a Sources panel you can expand. On desktop, hovering an inline link shows a preview card of the page. On mobile, the sources collapse into a tap-to-open list, so that hover preview is a desktop convenience, not the citation itself.
The most useful thing to know is the tell. Per OpenAI's documentation, a ChatGPT Search answer carries inline citations plus a Sources button, so in practice, no visible evidence it used search means ChatGPT did not search the web for that answer. It answered from parametric memory, the patterns the large language model absorbed during training, and cited nothing, even when it sounds just as sure of itself.
That distinction is the foundation for everything below. A citation only exists when ChatGPT actually searched, and what it shows you is a filtered slice of what it read, not the whole list. The glossary entry on an AI citation defines the term; this piece is about the machinery behind it, which starts with how AI search works.
How ChatGPT Decides What to Cite
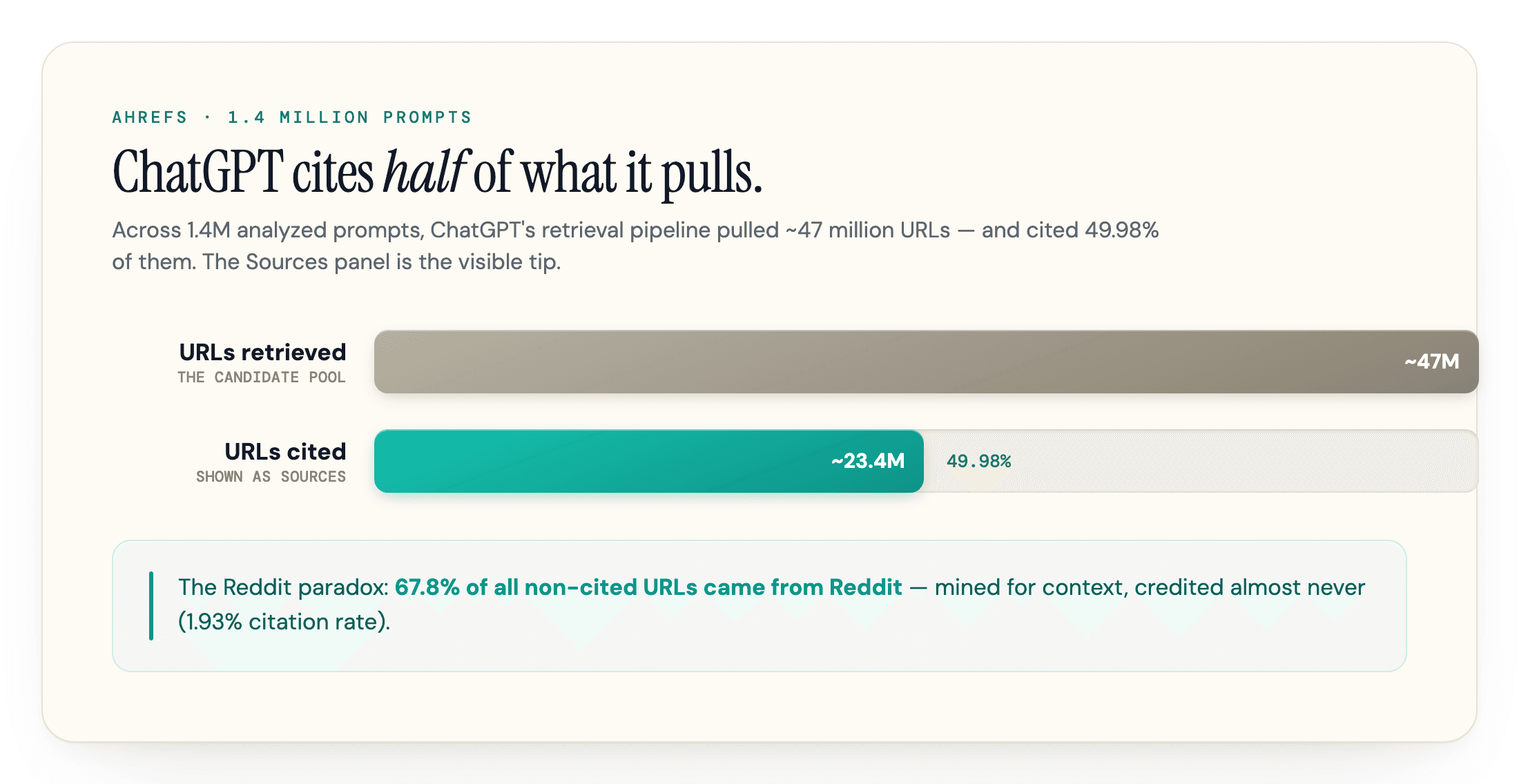
ChatGPT cites only about half of the URLs it retrieves. When it searches, it fires several queries, pulls back a candidate pool of pages, and then cites roughly one in two. Ahrefs analyzed 1.4 million ChatGPT prompts and found the model cited 49.98% of the URLs it retrieved, about 23.4 million cited pages out of roughly 47 million pulled, while some of the rest were likely never opened at all — the figure tracks the full journey from retrieval to citation, not a read-then-discard decision. So the Sources panel is the visible tip of a much larger set of pages its retrieval pipeline pulled.
What survives the cut depends heavily on the type of source. The same study scored citation rates by source type, and the spread is enormous.
| Source type | Citation rate |
|---|---|
| Search-index pages | 88.46% |
| News | 12.01% |
| 1.93% | |
| YouTube | 0.51% |
| Academia | 0.40% |
Two more findings cut against common assumptions. Among search-index results, the median cited page was around 500 days old, about 1.3 years, so relevance can outweigh raw freshness for ChatGPT (the opposite of Perplexity's live-first bias, which we cover in ChatGPT vs Perplexity). And in that same slice, pages with natural-language URL slugs were cited at 89.78% versus 81.11% for those without, a small but real edge for clean URLs.
Why Search-Index Pages Dominate
The 88% figure for search-index pages is doing a lot of work. ChatGPT Search runs on a web index, and the pages it already finds through that index are the ones it trusts enough to cite. News, Reddit, and YouTube get read for context and color, but the citation usually lands on a page that was retrievable and rankable in the first place. Classic discoverability still gates everything: if your page is not in the index ChatGPT searches, it cannot be the one-in-two that gets cited.
Fan-Out: One Question, Many Searches
When you ask one question, ChatGPT does not run one search. It expands your prompt into several related sub-queries, a process called fan-out, and pulls a candidate pool from all of them. It then scores those candidates against the answer it is drafting and keeps the closest matches, which is why roughly half the pool is dropped. A page can be solid and still lose its slot because another source matched the specific sentence better. Being retrievable gets you into the pool; being the clearest match for a passage is what earns the citation. The cross-engine version of that playbook is our guide to getting cited by AI.
The Reddit Paradox: Read but Not Credited
ChatGPT retrieves/pulls Reddit constantly and almost never credits it. In the same analysis, 67.8% of all non-cited URLs came from Reddit, even though Reddit's own citation rate was just 1.93%. Those URLs were not necessarily opened — Reddit and YouTube arrive via a separate API feed — but the model mines Reddit threads for context, opinions, and phrasing, then writes the answer and cites a cleaner-looking source instead.
This is the gap most people miss: retrieval is not citation. Your page can be pulled into the candidate pool, shape the wording of the answer, and never appear in the Sources panel. Being read is not the same as being cited, and the panel quietly undercounts what actually influenced the response.
Why does it swap in a different source? The model leans toward a citation that looks authoritative and self-contained (a clean article over a sprawling forum thread), even when the thread is where the substance came from. So a Reddit discussion can shape the answer while a tidy blog post takes the visible credit.
One denominator note keeps these numbers honest. The 1.93% above is the rate at which retrieved Reddit URLs earn a citation, not Reddit's slice of the citations you actually see. By share of all citations, Reddit sits near the top of the table: Profound's February 2026 study of roughly 730,000 US ChatGPT conversations with web citations (October to December 2025 data) measured Reddit at about 3% of all citations, and a May 2026 5W Public Relations audit put it at 11.97%, second only to Wikipedia's 13.15%. The two numbers differ by a factor of four because the studies are built differently: Profound counted one dataset from late 2025, while 5W synthesized nine datasets reaching into spring 2026, and as the sections below show, these shares move fast enough that the window matters. What they agree on is the rank, with Reddit at or near number two. Both pictures are true at once: ChatGPT retrieves so much Reddit that even a tiny per-URL citation rate leaves Reddit among its most-cited domains. Whenever you compare citation stats, check the denominator first.
For a brand, that has a blunt consequence. If your category lives on Reddit, ChatGPT is probably reading those threads, but the visible credit is going somewhere else, and only the visible credit is measurable from the Sources list.
How Citations Differ by Mode
There is no single "ChatGPT citation" behavior, because ChatGPT is several products wearing one name. How (and whether) it cites depends on the mode you are in.
| Mode | Does it cite? | How sources show | What to expect |
|---|---|---|---|
| Plain chat (no search) | No | Nothing | Answer from parametric memory; no Sources button |
| Search | Yes | Inline links + Sources panel | A handful of cited pages behind a one-shot web search |
| Deep Research | Yes, heavily | Many inline citations + a long source list | Dozens of sources across many searches; the most source-dense mode |
| Shopping | Yes | Product cards with merchant links | Sources are retailers and product pages, not articles |
| Agentic browser (Atlas) | Yes | Links to pages it visited | Links pages from the agent's browsing session (observed behavior; not an official citation spec) |
The practical takeaway is that the same question can produce zero citations in plain chat and twenty in Deep Research. If you are checking whether ChatGPT cites you, the mode you test in changes the answer. And because each mode searches differently, a page cited in Deep Research is not guaranteed to surface in a quick Search answer.
Why ChatGPT Gets Citations Wrong
A ChatGPT citation tells you where the model looked, not whether it looked correctly. When Columbia Journalism Review's Tow Center ran a 1,600-query news-attribution test across eight AI search engines, more than 60% of the answers carried incorrect citations. ChatGPT Search misidentified 134 of 200 source articles, hedged with uncertainty language only 15 times, and never once declined to answer. It was confidently wrong far more often than it was cautiously right, and the study found the premium tiers answered more confidently, not more accurately, than the free ones.
| Engine | Incorrect answers (news attribution) |
|---|---|
| Perplexity (best) | 37% |
| ChatGPT Search | 67% (134 of 200) |
| Grok-3 (worst) | 94% incorrect; 154 of 200 cited links broken |
Part of this is history. The University of Arizona Libraries notes that early ChatGPT routinely fabricated citations because it could not search the web and was built to produce plausible text, not retrieve real references. Web search reduced that, but did not erase it. Headlines still get invented, bylines still land on the wrong outlet, and links still point at scraped copies rather than the original.
Licensing Doesn't Save You
A licensing deal with OpenAI does not guarantee accurate credit. An earlier Tow Center study from November 2024 found ChatGPT citing partner publishers like the New York Post and The Atlantic inaccurately. The March 2025 follow-up separately found ChatGPT crediting a Yahoo-republished copy of a USA Today article even though USA Today had blocked its crawler. For a brand, that means the credit for your own work can land on a scraper, and a claim can carry your name without ever coming from you. It is the same machinery behind why AI gets your brand wrong, and the deeper dive there covers what to do about it.
How to Read and Trust the Sources ChatGPT Shows You
Treat the Sources panel as a starting point, not a verdict. Two facts from above should change how you read it: the panel undercounts what the model actually used, and a meaningful share of cited links are wrong or broken. A source appearing next to a claim is not proof the source supports that claim.
A 30-Second Citation Check
A quick way to check any ChatGPT citation:
- Click through. A cited link can 404 or land on an unrelated page. If it does not open, the citation is worthless.
- Confirm the page actually says it. Read the cited page for the specific claim. ChatGPT regularly attaches a real source to a sentence that source never made.
- Watch for syndication. If the link is a republished or scraped copy, find the original and cite that instead.
- Check the date. A confidently current-sounding answer can rest on a year-old page, given the ~500-day median.
- Re-ask. Run the same prompt again. If the sources change, you are seeing how unstable a single snapshot is.
The thirty seconds this takes is the difference between quoting ChatGPT and quoting whatever ChatGPT half-read. For anything you publish or send a client, the citation is a lead to verify, not a citation to trust.
Do ChatGPT's Citations Stick Around?
Cited Links Rot
A ChatGPT citation is a snapshot, not a permanent record. The link points to the live web, so if the page changes, moves, or comes down, the citation rots the way any bookmark does. Open an old chat months later and a source that once backed the claim may now 404, redirect, or show different content than the model summarized.
The Source Set Moves
There is a second kind of impermanence that matters more for visibility. Because ChatGPT re-runs the search every time, the source set itself is not fixed. The page it cited for a query last month may not be cited this month, even when nothing about your page changed, because the candidate pool and the model both shifted underneath it. A citation you earned is not a citation you keep, which means a screenshot of the Sources panel is evidence of one moment, not a standing fact.
The swings are not subtle. When Semrush tracked 230,000 prompts weekly from July 14 to October 12, 2025, the share of ChatGPT responses citing Reddit collapsed from close to 60% in early August to around 10% by mid-September 2025, and Wikipedia fell from roughly 55% of responses to under 20% over the same study window (those are shares of responses, a different denominator from the citation shares earlier). Model updates move the set too: a SISTRIX analysis of 3.8 million German-language ChatGPT responses found that when ChatGPT's model identifier switched to GPT-5.5 on May 22–23, 2026, citation patterns that normally drift 1 to 2% a day shifted 47% in 48 hours, and the average number of cited sources per response dropped from 30.9 to 28.4. Nothing about those pages changed. The engine did. The next such shift is already here: OpenAI released GPT-5.6 (GA July 9, 2026), and now that it is in ChatGPT it will reshuffle the citation set again.
How to Measure Which Sources ChatGPT Cites for You
There is no ChatGPT Search Console. Google hands you a dashboard of the queries you rank for; ChatGPT hands you nothing, so the sources it shows for your category are invisible unless you go looking on purpose.
The manual method works for a quick read. Write down the prompts a real customer would ask about your category, such as "best [your product] for [use case]" or "is [your brand] worth it," run each one in the mode your audience uses, and log which sources appear in the panel. Repeat it on a schedule, because the results move. In the scans we run for our own brand prompts, the same prompt can return a different source set day to day, so a single check tells you almost nothing, and the only useful signal is the trend across many runs.
That is also where the manual method runs out. Tracking dozens of prompts across modes, week after week, by hand is not realistic, which is the gap geotoolbox is built to close: its visibility tracker re-runs your prompts on a schedule (the free plan covers ChatGPT; paid plans add more engines), and citation tracking on the paid plans logs which sources surface over time. The broader metric this rolls up into is your AI share of voice, and the tooling view is an AI rank tracker. Both exist to make the source picture visible instead of guessed at.
What This Means If You Want to Be Cited
If the goal is to be the page ChatGPT cites, the mechanics above point to three things, and none of them is a new trick. Be in the index it searches, which means allowing OAI-SearchBot through your robots.txt and firewall — that is the crawler that gates ChatGPT Search inclusion. GPTBot controls training data opt-out, not search. Be the clearest, most quotable source on the question, because the model favors pages it can lift a clean answer from. And give it the signals it rewards.
The field is also more open than the big-domain headlines suggest. In Profound's February 2026 analysis of roughly 730,000 US ChatGPT conversations, the ten most-cited domains captured only about 12% of all citations, with Wikipedia first at just 5%. Trackers built on other windows and methods put the top domains higher (the 5W audit above has Wikipedia and Reddit alone over 25% combined), but every large study agrees on the shape: most of ChatGPT's citations go to a long tail of ordinary sites that were the cleanest, best-corroborated answer to a specific question.
Check the gate first
Before ChatGPT can cite you, a crawler has to reach you. The free AI Crawler Checker shows which AI crawlers your robots.txt allows or blocks, with the exact line to fix.
That last point has data behind it. The Generative Engine Optimization study (Aggarwal et al., IIT Delhi and Princeton, KDD 2024) found that its top tactics, citing sources, adding quotations, and adding relevant statistics, each lifted a source's visibility in generated answers by roughly 30 to 40%. Concrete, well-sourced, quotable writing is what gets pulled into the citation set.
The full getting-cited playbook, including the OpenAI crawlers and what ChatGPT actually rewards, is in SEO for ChatGPT, and the engine-agnostic workflow is in how to optimize for AI search. Start there once you understand the machinery on this page.
Citations You Can See Are Citations You Can Fix
ChatGPT's citations are a filtered, often-wrong, mode-dependent slice of what it read, not a clean bibliography. Once you know that, the panel stops being a verdict and becomes a working surface: every link in it is something you can verify, correct, or compete for. Understanding that is what separates quoting ChatGPT from being quoted by it.
The one move that pays off no matter what is to stop guessing. If you have never looked at which sources ChatGPT shows for your category, the citation tracking in geotoolbox gives you that view across the engines on your plan. It reads the same Sources panel ChatGPT shows everyone, the cited half rather than the full retrieval pool, but the cited half is the half you can act on. You cannot fix a citation you cannot see.
Frequently Asked Questions
Can I make ChatGPT cite its sources?
Yes. Toggle the web-search tool on, or ask it directly to search the web for the answer, and the response comes back with inline citations and a Sources panel. Without a live search there is nothing for it to cite, so forcing the search is the only reliable way to get sources on demand.
Does blocking OpenAI's crawlers remove my site from ChatGPT citations?
Blocking OAI-SearchBot removes your pages from ChatGPT Search results, and with them your citations, over time. Blocking GPTBot only opts you out of model training, not search. And blocked content can still surface indirectly: syndicated copies on sites that allow the crawlers can get cited in your place, as USA Today found.
How do I spot a fabricated ChatGPT citation?
The tell is plausibility without traceability: a real author paired with a paper that does not exist, or a journal that checks out while the article title does not. Paste the exact title into a search engine; if nothing comes back, the reference is invented, no matter how polished it looks.
Why are the links ChatGPT cites sometimes broken?
Three mechanisms: the model can return a URL from retrieval without re-fetching it to confirm it still resolves, it sometimes links syndicated or scraped copies whose hosts later pull them down, and in the worst cases a generated URL was never valid at all. Click-testing the link is always step one.
How do I cite ChatGPT in an APA or MLA paper?
That is the other meaning of "ChatGPT citations" and a separate question from this article. Both APA and MLA treat ChatGPT output as a non-recoverable source and publish their own current formats, so follow the official APA Style and MLA Style guidance for the exact template.
Sources
- 5W Public Relations - Wikipedia and Reddit Now Drive Over 25% of ChatGPT Citations in the US (May 2026) -
prnewswire.com/news-releases/wikipedia-and-reddit-now-drive-over-25-of-chatgpt-citations-in-the-us-new-5w-research-finds--wsj-nyt-and-bloomberg-do-not-appear-in-the-top-20-302768339.html - Ahrefs - Why ChatGPT Cites One Page Over Another (1.4M-prompt study) -
ahrefs.com/blog/why-chatgpt-cites-pages - Columbia Journalism Review, Tow Center - AI Search Has a Citation Problem (March 2025) -
cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php - Columbia Journalism Review, Tow Center - How ChatGPT Misrepresents Publisher Content (November 2024) -
cjr.org/tow_center/how-chatgpt-misrepresents-publisher-content.php - GEO: Generative Engine Optimization (Aggarwal et al., IIT Delhi/Princeton, KDD 2024) -
arxiv.org/abs/2311.09735 - OpenAI Help Center - ChatGPT Search -
help.openai.com/en/articles/9237897-chatgpt-search - Profound - How ChatGPT Sources the Web (~730,000-conversation study, February 2026) -
tryprofound.com/blog/chatgpt-citation-sources - Search Engine Journal - GPT-5.5 Update Changes How ChatGPT Cites Sources (SISTRIX data, June 2026) -
searchenginejournal.com/chatgpt-citations-changed-after-gpt-5-5-sistrix-data-shows/577694 - Semrush - The Most-Cited Domains in AI: A 3-Month Study (July-October 2025) -
semrush.com/blog/most-cited-domains-ai - University of Arizona Libraries - ChatGPT and citations -
ask.library.arizona.edu/faq/387173