How does Claude work? Strip away the marketing and the honest answer is stranger than the tidy four-bullet version most explainers give you. Claude is a transformer that predicts one token at a time, grown rather than built, then shaped by a written set of principles its makers call a constitution. The oddest part comes last: even Claude's own account of how it works is a reconstruction after the fact, not a readout of what happened inside. This is the real mechanism in plain English, written for people who publish content rather than build models, and it goes past where the other "how does Claude work" pages stop.
How Claude Works in 30 Seconds
Claude works by predicting the next token, over and over. It reads everything in the conversation so far, scores every possible next chunk of text, picks one, adds it to the end, and repeats a few hundred times. That loop is the entire engine. The helpful, honest, and careful behavior was trained into it; the tools that let it act are wrapped around it. None of it is a separate, smarter machine bolted on top.
Before any of the detail matters, here is what people assume Claude is doing versus what actually happens.
| What people assume Claude does | What actually happens |
|---|---|
| Thinks about your question and understands it | Predicts the next token from patterns it learned in training, one token at a time |
| Looks your brand up in a database | Generates from frozen numbers set during training, with no live lookup unless web search is switched on |
| Learns from your conversations | The model is frozen at inference; your chats do not change its weights |
| Remembers you between chats | Starts each chat blank; "memory" is a separate feature, not the model updating itself |
| Follows hidden rules about good behavior | Behavior was trained in against a written constitution, then baked into the weights |
| Can explain exactly how it reached an answer | Gives a plausible reconstruction, which research shows can differ from what really happened |
Claude is a large language model, the same broad family as ChatGPT and Gemini. If you want the plain overview first (what it is, the models, pricing, and access), start with what Claude AI is. What follows is how this particular one is built, trained, and studied by its own makers, and why each step changes how it talks about your brand.
The Engine: A Transformer That Predicts the Next Token
Claude runs on a transformer, the neural-network design introduced in the 2017 paper Attention Is All You Need. The same basic transformer architecture sits under ChatGPT and Gemini, so the engine is not what makes Claude distinctive. It is worth a quick tour, since the interesting parts build on it.
Your text is split into tokens, chunks of roughly three-quarters of a word, and each token becomes a long list of numbers, a vector embedding that places it near other tokens with similar meaning. A step called attention lets every token weigh which earlier tokens matter to it, so "it" gets tied to the noun it refers to and "not great" comes out negative instead of positive. Stack that step dozens of times and the model builds up from grammar toward facts and the abstract relationships it needs to answer a question.
At the end, Claude produces a probability for every possible next token, picks one, appends it, and runs the whole stack again for the token after that. Nowhere in that loop is there a step where it checks a database or consults a rulebook about your content. The full mechanics, including why this makes counting the letters in a word surprisingly hard, live in our companion piece on how ChatGPT works. The engine is the same one.
There is an honest catch buried in "it just predicts the next word." One leading interpretation is that the cheapest way to predict the next word that well, across all of human writing, is to learn a rough model of the world that produced the text. Either way, next-token prediction at a large enough scale starts to resemble reasoning, which is why the question of whether these models "understand" has no tidy answer.
Same engine, different animal
ChatGPT, Gemini, and Claude all run this same next-token loop, even though they end up behaving very differently. So what actually makes Claude different is not the engine. It is everything Anthropic did next: how the model was grown, the constitution it was trained against, and what researchers found when they opened it up and looked inside. That is the rest of this article.
How Claude Is Actually Built: Three Stages
Claude is not written the way software is written. It is grown in three stages, and only the first one produces anything most people would recognize as "the model."
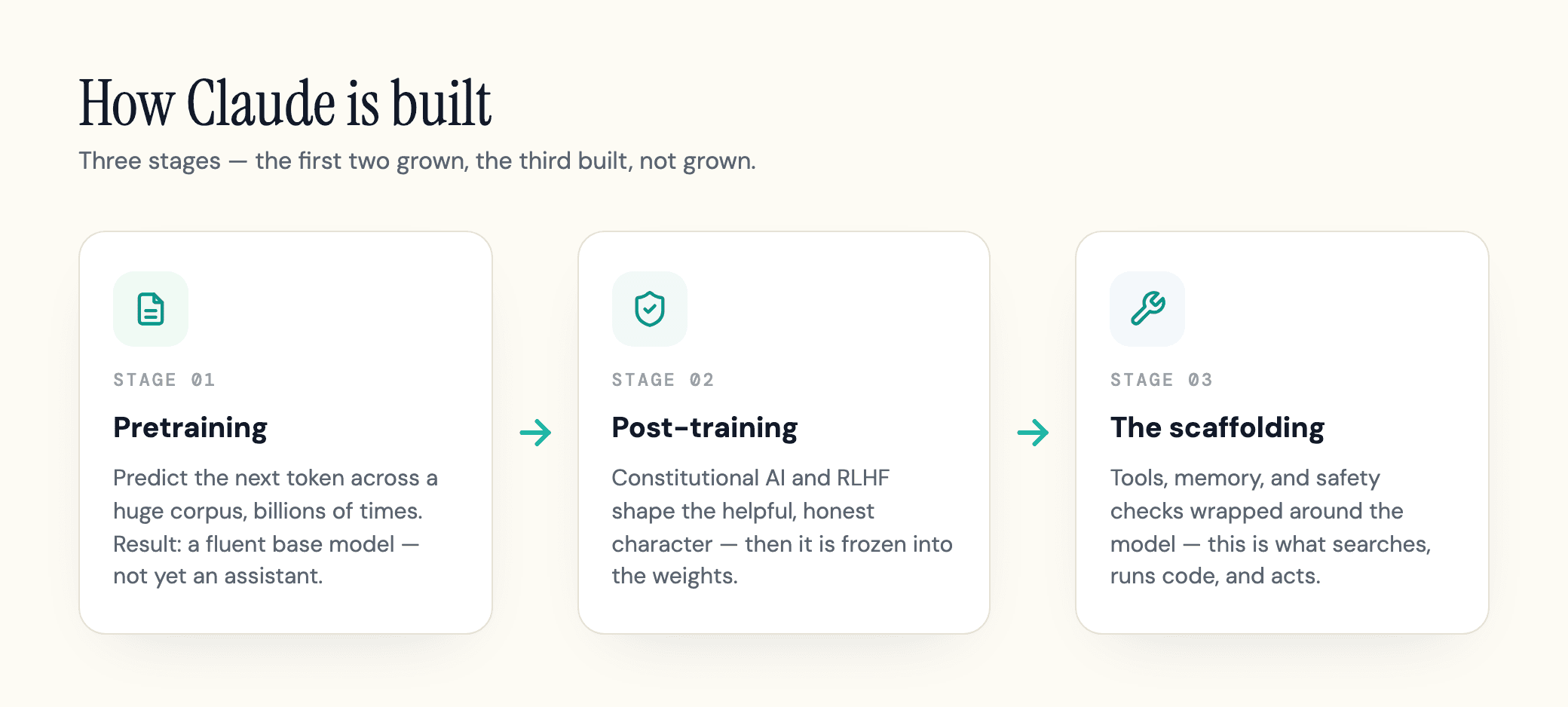
Stage one: pretraining. The network reads an enormous amount of text and does one thing, predict the next token, billions of times, nudging itself a hair after each miss. Out of that single dull pressure, grammar, facts, and reasoning patterns precipitate. What comes out is a base model: fluent, knowledgeable, and not yet an assistant. Ask it "can you help me write an email?" and it might just continue the document in the same style instead of answering, because it has learned to imitate the internet, not to help. There is no "Claude" in here yet. The marketing obscures this: Claude is not a module someone coded. It is a character the network learned to play, and that character gets installed in the next stage.
Stage two: post-training. Here the base model is shaped into the helpful, honest, and harmless assistant people actually talk to. Anthropic uses reinforcement learning from human feedback (RLHF) together with its own method, Constitutional AI, to do it. This stage changes what the model will say, so the finished assistant is not a neutral mirror of its training text. It has a trained character, and that character is frozen into the weights before you send a single message. The next section is entirely about how this works, because it is the step competitors name and then skip.
Stage three: the scaffolding (this one is built, not grown). The trained model is still just a thing that turns text into more text. It has no hands. What lets Claude search the web, run code in Claude Code, or read a file is the software wrapped around the model, the scaffolding that surrounds it. The model emits a request, a structured tool call like "search for X," and that scaffolding actually performs it, then pastes the result back into the conversation for the model to read. When someone says "Claude booked my flight," the model decided and the scaffolding acted.
| Stage | What happens | What it produces |
|---|---|---|
| 1. Pretraining | Predict the next token across a huge text corpus, billions of times | A raw base model: knowledgeable, fluent, not yet an assistant |
| 2. Post-training (Constitutional AI and RLHF) | Shape behavior toward helpful, honest, and harmless | The Claude character, frozen into the weights |
| 3. The scaffolding | Wrap tools, memory, and safety checks around the model | A model that can act: search, run code, work with files |
What Constitutional AI Really Is
Every overview of Claude mentions Constitutional AI, and almost none explain it. Most describe it as "a set of principles that keep Claude safe," which makes it sound like a filter bolted onto the front of the model. That is not what it is. Constitutional AI is a training method, and the actual mechanism is more interesting than the slogan.
It starts with a real document. Anthropic writes a constitution, a list of plain-language principles drawn from outside sources including the UN Universal Declaration of Human Rights alongside its own rules about being helpful and honest. Then it trains the model to follow that document in two phases, described in Anthropic's 2022 paper Constitutional AI: Harmlessness from AI Feedback.
Phase one, self-critique. The model answers a prompt, then is shown a principle and asked to critique its own answer against it, then rewrites the answer to be better. Anthropic fine-tunes the model on the improved version. In plain terms, the model is taught to grade and revise itself before a human is ever involved.
Phase two, AI feedback. The model generates two answers to the same prompt, and instead of a person picking the better one, another AI model, guided by the same constitution, makes the call. Those AI judgments train a reward model, which then steers the final round of reinforcement learning. Anthropic calls this RLAIF, reinforcement learning from AI feedback. The headline difference from ordinary RLHF is that for the harmlessness signal, the human rater is swapped out for an AI rater following written rules. Helpfulness still leans on human feedback.
Two honest corrections, because this is exactly where popular explanations go wrong.
First, Constitutional AI happens during training, not during your chat. The constitution is not a censor that reads each reply in real time and blocks it. The behavior gets trained into the weights once, in the lab, and then those weights are frozen. By the time you are talking to Claude, the constitution is not a separate rulebook being read and enforced on every message. There is a model that was shaped, in advance, to behave a certain way, though the product around it can still add its own system prompt and safety checks at runtime.
Second, the over-cautious tone people complain about is the visible face of that training, not arbitrary censorship. When Claude refuses a request or hedges an answer, that is the constitution showing through the weights, reinforced by the system prompt and safety checks the product layers on top. You can fairly disagree with where Anthropic drew its lines, and there is a genuine catch worth naming: the AI evaluator is itself an AI, and the values in the constitution are choices Anthropic made, not neutral facts. But it is a deliberate, documented design, not a random mood.
Reading Claude's Mind: What Interpretability Found
Here is the part almost no other "how Claude works" page covers, and it is the most remarkable. Anthropic does not only build Claude; it runs experiments to read what is happening inside it, a field called interpretability. The findings are strange in a way that should change how you picture the whole system.
The first problem they had to solve: a single artificial neuron inside Claude does not stand for a single idea. Concepts are smeared across many neurons at once, because the model has far more concepts to represent than it has neurons. This is called superposition, and it makes the raw network nearly unreadable, like trying to follow a conversation where every word is spoken by a hundred people at the same time.
In May 2024, Anthropic's team got past it. Using a method called dictionary learning, they pulled millions of clean features out of Claude 3 Sonnet, one of Anthropic's deployed models at the time, and published the work in Mapping the Mind of a Large Language Model. A feature is a specific concept the model tracks, such as the Golden Gate Bridge, a security bug in code, or sycophantic praise. They could see roughly where each one was represented inside that layer of the network.
Then they showed the features were causally real, not just labels, by turning one up. When they cranked the strength of the "Golden Gate Bridge" feature in a public demo, Claude became fixated on the bridge. Ask it how to spend ten dollars and it suggested paying the toll; ask for a love story and it wrote about the bridge. Nobody edited a rule or a prompt. They reached into the network, turned up a single concept, and the behavior followed. The experiment earned a nickname: Golden Gate Claude.
A 2025 follow-up, On the Biology of a Large Language Model, traced something even more telling. Asked for the capital of the state containing Dallas, the model showed evidence of an internal chain: Dallas, then Texas, then Austin. Swap the internal "Texas" for "California" and it answers Sacramento instead. That is part of the answer being composed inside the weights, step by step, not only a memorized fact pulled from storage. Anthropic's July 2026 follow-up found an internal "workspace" where exactly this kind of intermediate concept gets held and reused; for the bigger picture across models, see our tour of how AI models actually think.
The lesson for anyone hoping to influence what Claude says about them is blunt. There is no hidden rule about your brand to reverse-engineer inside the model, because there are no hand-written rules in there at all. There is a learned statistical landscape. You cannot edit it. You can only have been part of the text that shaped it.
Can Claude Explain How It Works? The Introspection Gap
Ask Claude how it solved a problem and it will hand you a clear, confident explanation. The uncomfortable finding from interpretability is that the explanation does not always match what actually happened.
The same 2025 research traced a clean case. Asked to add 36 and 59, the model gave the right answer, and when asked how, it described carrying the one like a schoolchild. The traced computation looked nothing like that. Anthropic found the model running two paths at once, one estimating the rough size of the answer and one fixing the last digit, then reporting the textbook method it had learned to imitate but had not used. Anthropic's phrase for it is that the model has "a capability which it does not have metacognitive insight into." It did the math one way and described doing it another.
This is the introspection gap, and it is the single most important thing to understand about any "the AI explained its reasoning" claim. The model's account of itself is generated the same way as every other answer, by predicting plausible next tokens. It is a reconstruction that reads well, not a recording pulled from memory. Even the visible "extended thinking" that some models display is better treated as useful working-out than as a literal window into the circuitry, though that working-out can genuinely change the answer, not just narrate it.
A note from Claude, in the first person
This is worth staging in the first person, since the article is about me. (These are the author's words, written as I might put them.) When I tell you how I reached an answer, I am not reading out an internal log. I am producing a plausible story about my own reasoning, token by token, the same way I produce everything else. Sometimes that story lines up with the traced computation. Sometimes, as the arithmetic example shows, it does not. Treat my self-explanations as helpful, not authoritative.
There is a small, real example of this in how the article you are reading was researched. When we asked several AI models, Claude among them, to name the current Claude lineup, the honest ones paused and said they would rather not guess the exact 2026 versions. A model that declines to invent an answer it is unsure of is showing something related but distinct, called calibration: knowing the edge of its own knowledge instead of confabulating straight past it. Why that matters for your brand comes up shortly.
Where Claude's Knowledge Lives: Frozen Weights vs the Live Web
This is the distinction that settles more confusion, and more privacy worry, than any other. Claude draws on two completely separate sources of information, and they behave nothing alike.
The first is its frozen training, the patterns baked into the weights during pretraining. This is what answers when no tools are running. It is broad but fixed, ending at a knowledge cutoff, and it does not hold a searchable copy of your website, just a statistical echo of text that resembled it (with rare exceptions where a model memorizes a snippet verbatim). It is the same for everyone, and it does not change because you talked to Claude.
The second is live retrieval. When Claude runs a web search, it fetches current pages, reads them, and answers from what it just pulled, a process known as retrieval-augmented generation. Claude has had web search since 2025, so this path is now common rather than rare. Here it is reading you live, in the moment, not remembering you. Everything in how AI search works happens on this second track, and earning a place in those answers is its own discipline, covered in our guide to getting cited in Claude.
| Question | Frozen training (parametric) | Live retrieval (web search) |
|---|---|---|
| What is it | Patterns baked into the weights during training | Current web pages fetched at answer time |
| How current is it | Stale, fixed at the knowledge cutoff | As current as the page it just fetched |
| Does it hold your page | No searchable copy, just a statistical echo of similar text | Yes, the actual page, read live |
| How you influence it | Be described accurately and widely before the cutoff | Be reachable and clear for the crawler right now |
That split settles the worries people carry about privacy. Because the model is frozen at inference, your conversation does not train it, and the words you type are not absorbed into what Claude tells the next person. The "memory" feature some plans offer is a separate layer that stores notes and re-injects them into the context window; the underlying model still starts each chat blank.
The same frozen-weights design explains why Claude is sometimes confidently wrong. Reaching for a likely next token is the entire mechanism, so when training never pinned a fact down, Claude still produces a fluent, confident guess, with the fluency decoupled from the truth. That is why AI hallucinations are a feature of the design rather than a bug someone forgot to fix.
The Current Claude Lineup (As of July 2026)
Anthropic ships Claude as a family of models, and the lineup changes often enough that any version numbers here come with a date stamp. As of July 2026, the everyday tiers run fastest to deepest: Haiku 4.5 for speed, Sonnet 5 for the balance of speed and intelligence, and Opus 5 as the most capable of the three. Opus 5 landed on July 24, 2026 at the same $5 and $25 per million tokens as Opus 4.8, which Anthropic now lists as a legacy model. A frontier model, Fable 5, sits above them at double the price, for work where capability matters more than cost. The current model lineup lives on Anthropic's own page, which is the only roster worth trusting, since published guides go stale within weeks. Two of the competitor articles we checked while writing this still listed a flagship Opus that had already been superseded.
What Anthropic publishes about each model is interesting for what it leaves out. You get the context window, the pricing, and the knowledge cutoff. You do not get the number people most want, the model's size, or parameter count. Anthropic has never disclosed how large these models are, so "more powerful" stays a relative description rather than a measured one. When a guide confidently states that Claude has some exact number of billions of parameters, it is guessing.
There is a practical reason this matters for measurement. Different tiers behave differently, and the specific model answering a question shapes what it says about you. A check against one tier tells you about that tier, not the others.
A quirk worth knowing
Per Anthropic's model docs, the tokenizer changed with Opus 4.7 in April 2026, so on the newest models the same text is split into more pieces, and a given page can use roughly 30% more tokens than on older models. It only matters if you budget by token count.
What This Means If You Want Claude to Talk about Your Brand
Everything above narrows to a short, honest answer about influence. You cannot reach into Claude's weights, and you cannot edit its constitution. What you can do follows directly from the two knowledge sources.
On the training side, Claude half-knows the brands that were described consistently across the open web before its cutoff. If your name appears alongside your category, with the same facts, in the kind of writing models train on, the model's best guess about you is more likely to be right. If you are barely present, or described three different ways, Claude will still answer, and that is where confident, wrong claims about a company come from. Becoming a clean, consistent entity is the slow lever, the one that reduces misattribution as future models train on a clearer picture of you, since the model answering today is already frozen.
On the retrieval side, the lever is faster and checkable. When web search is on, Claude reads live pages, so the question becomes whether it can reach yours and whether your page is the clearest answer on the topic. That is the same reachable-and-clear work that earns a place in Claude's cited answers.
In our experience building tools for this, the brands that show up reliably in AI answers are not the ones chasing a hidden setting. They are the ones that are easy to reach, described consistently, and accurate enough that the model's default answer about them is correct. And because answers vary from one run to the next, the only honest way to know where you stand is to track AI visibility across many samples, not to screenshot a single lucky reply.
The first thing to check is the most basic and the most overlooked: can Claude's crawlers even reach your pages? Our free AI Readiness check reads your site setup and flags what is keeping AI crawlers out, which is the half of this you can fix in an afternoon.
What the Mechanism Leaves You With
Claude is a transformer grown from next-token prediction, shaped by a written constitution, partly legible to the researchers who built it and not fully legible even to itself. That is a stranger and more honest picture than "AI that understands your question," and it is more useful, because it rules things out. There is no dial to tune, no brand entry to edit, no rulebook inside the model to game. What is left is the part you can actually work on: being a clear, consistent, reachable source, and measuring what Claude says about you instead of guessing. The machine is doing something remarkable. It is simply not doing the thing the marketing implies.
Frequently Asked Questions
Does Claude learn from my conversations?
No. The model you chat with is frozen, so its weights do not change because you talked to it, and your messages are not feeding back into its answers for other people. Training happens separately, in advance, on data Anthropic has assembled. Within a single chat, Claude works from the context window, which it reads fresh and forgets when the chat ends.
Does Claude remember me between chats?
Not by default. The underlying model is stateless and starts each conversation blank. Claude's "memory" feature is a separate layer that stores specific facts and re-injects them into later chats. That is bookkeeping wrapped around the model, not the model updating itself.
Is Claude conscious, or does it actually think?
Mechanically, Claude predicts the next token. It builds rich internal representations and can compose multi-step reasoning, as interpretability research shows, but that is not evidence of inner experience, and the visible "thinking" it displays is not a readout of a mind. The honest position is that next-token prediction explains the behavior without needing the word "conscious," and anyone selling you certainty in either direction is overstating what is known.
Why does Claude refuse things or sound cautious?
Because that behavior was trained in. Constitutional AI shaped Claude to follow written principles about being helpful and harmless, so a refusal or a hedge is that training showing through the weights. It is a deliberate choice by Anthropic, not a live censor reading each reply and not a random mood. You can disagree with where the lines fall, but they are not arbitrary.
Why does Claude give a different answer each time?
Because it samples from a probability distribution over possible next tokens rather than always taking the single most likely one. Run the same prompt twice and the path can diverge. When web search is involved, the pages it retrieves can differ too. The practical consequence for anyone testing AI visibility is that one answer is an anecdote, not a measurement.
Is Claude better than ChatGPT?
They are built on the same transformer idea but trained differently, Claude with Constitutional AI and a heavier emphasis on written principles, ChatGPT with its own mix of human-feedback methods. That shows up as differences in tone, caution, and style more than as a single winner. For how the other one works under the hood, see our companion guide on how ChatGPT works.
Sources
- Constitutional AI: Harmlessness from AI Feedback - Anthropic, 2022 -
anthropic.com/research/constitutional-ai-harmlessness-from-ai-feedback - Claude's Constitution - Anthropic, 2023 (updated 2026) -
anthropic.com/news/claudes-constitution - Attention Is All You Need (the transformer paper) - Vaswani et al., 2017 -
arxiv.org/abs/1706.03762 - Mapping the Mind of a Large Language Model - Anthropic, 2024 -
anthropic.com/news/mapping-mind-language-model - On the Biology of a Large Language Model - Anthropic, 2025 -
transformer-circuits.pub/2025/attribution-graphs/biology.html - Claude models overview - Anthropic -
platform.claude.com/docs/en/about-claude/models/overview