Claude vs Gemini is usually framed as a contest with a winner. It is not one. As of July 2026 Anthropic's Claude and Google's Gemini are close enough at the frontier that the honest answer is "it depends on the task," and the two land in genuinely different places: Claude leans into writing and careful reasoning, Gemini into live search, multimodal, and the Google ecosystem it lives inside. There is also a third question almost nobody asks, and it matters most if you publish: which one cites your brand when a customer asks. This is the comparison done honestly, written for people who publish content rather than build models. New to either? Start with what Claude AI is or what Google Gemini is.
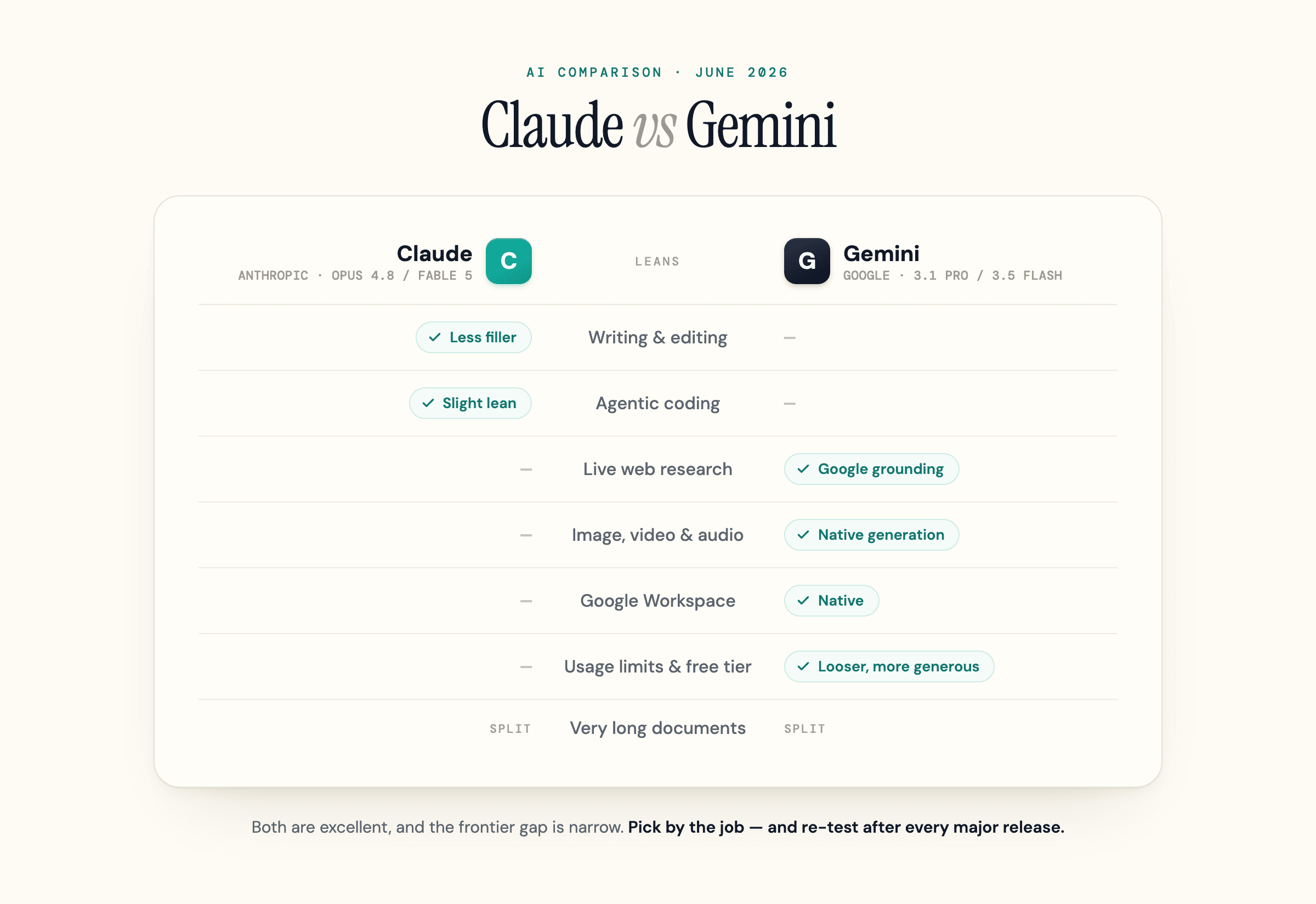
Claude vs Gemini at a Glance (July 2026)
Here is the honest version before the detail. Both are excellent, and the real differences sit at the edges that matter to your specific work. Model versions move fast here, faster than most comparisons admit, so everything below is dated to July 2026 and worth re-checking before you act on it.
| Claude | Gemini | |
|---|---|---|
| Maker | Anthropic | Google (DeepMind) |
| Top models (July 2026) | Opus 5, Sonnet 5, and the higher-tier Fable 5 (Opus 4.8 now legacy) | Gemini 3.1 Pro (still in preview) and 3.6 Flash, with Gemini 3.5 Pro rolling out |
| Leans best at | Long-document work, writing, agentic coding | Live web research, multimodal work, and anything inside Google Workspace |
| Entry price | Pro around $20/month | Google AI Pro around $20/month (AI Plus around $5) |
| Context window | Up to 1M tokens on Opus 5 and Sonnet 5, in the app as well as the API | 1M tokens on Gemini 3.1 Pro; Gemini 3.5 Pro is rumored at 2M (no official spec yet) |
| Web search and citations | Web search built in; fewer, more authoritative citations; strong at grounding a document you give it | Grounded in live Google Search; Deep Research across many sources; more real-time coverage |
| Multimodal | Text, image, and document input; no native image, video, or audio generation | Generates images, video, and audio (via Google's media models); multimodal input |
| Standout feature | Claude Code; the careful, low-fluff character | Deep Google Workspace integration; native media generation |
| Free tier | Yes (a Sonnet-class model) | Yes (the Gemini app, with limits) |
Both are large language models built on the same basic idea, so a feature checklist only gets you so far. The differences that actually predict which one you will prefer come from how each was trained and how each handles the live web, which is where the real decision lives.
Is Claude Better Than Gemini?
No, and neither is the other one. "Better" is the wrong question, because the answer flips by task. The honest split is clear: Claude tends to win on long-form writing and careful, low-fluff reasoning, Gemini wins on live research, multimodal work, very long context, and anything that touches Google Workspace, and coding is genuinely contested. Most people who lean on either one heavily end up using both, the same pattern we found comparing Claude vs ChatGPT.
That sounds like a dodge, so here is the specific shape of it. If your day is drafting, editing, and reasoning over long documents, Claude usually feels sharper and less padded. If your day involves pulling current information off the live web, generating an image or a video, working across a 2-hour meeting transcript, or living inside Gmail and Docs, Gemini's reach is hard to match because it is built into the products you already use. For code, the picture is close and depends on the job, which is a contradiction worth taking seriously rather than explaining away.
There is one practical catch that the "just pick the smarter model" advice ignores, and it is the single most common complaint we see from heavy Claude users: usage limits. Claude's paid tiers cap how much you can send in a window more tightly than Gemini's, and people hit that wall mid-task. Gemini's limits are generally looser, and its free and low-cost tiers are more generous. A model that is slightly better per answer but stops you cold is not obviously the better tool, which is a real reason Gemini wins for some people who never argue it is the smarter model.
So the useful question is not which one is better. It is better at what, for whom, and measured how, which is what the rest of this comparison gets specific about.
How Claude and Gemini Actually Work (and Why You Feel the Difference)
Under the hood, both run the same kind of engine and then diverge in two ways that explain most of how they behave. Each is a transformer that predicts the next token, trained on a large slice of the internet. The character you talk to comes from a second stage, alignment, and from the product wrapped around the model. Both of those diverge sharply between Claude and Gemini, and that is the part most comparisons skip.
The training recipe differs. Claude's behavior is shaped by reinforcement learning from human feedback plus Constitutional AI: the model first critiques and revises its own answers against a written set of principles, and the reinforcement step is then driven by preferences an AI generates against those same principles, rather than by human ratings alone. Gemini comes out of Google DeepMind with a different emphasis: it was built to be natively multimodal, trained on text, images, audio, and video together rather than having vision bolted on afterward, which helps how it works across media. Different recipes, different defaults. We cannot inspect either model from the outside, so treat any claim about why it behaves a certain way as an informed read, not a readout. The deeper mechanism lives in our companion pieces on how Claude works under the hood and how ChatGPT actually works, whose mechanics apply to any transformer.
The second divergence is the product, and it matters more than the model for most daily decisions.
| The model | The product | |
|---|---|---|
| What it is | A trained network that turns a prompt into more text | The app around it: tools, memory, web search, media generation, integrations, safety, UI |
| Claude | Opus 5 / Sonnet 5 / Fable 5, shaped by Constitutional AI | claude.ai and Claude Code: web search, file handling, artifacts, agentic coding |
| Gemini | Gemini 3.1 Pro / 3.6 Flash (multimodal input, text output) | The Gemini app and Workspace: live Google Search, image and video generation via Google's media models, Gmail and Docs, Deep Research |
When people say "Gemini can make a video" or "Gemini is right there in my Gmail," they are usually describing the product, not the raw model. Keeping the two apart is the difference between a comparison that holds up and one that ages badly the next time either company ships a feature. A capability gap today is often a product decision, not a permanent limit of the underlying model.
How Each One Searches the Web and Cites Sources
This is where the two pull furthest apart. A model only knows the world up to its training cutoff. As of July 2026 that is around May 2026 for Claude Opus 5, per Anthropic's docs — four months fresher than the legacy Opus 4.8 and Sonnet 5, which both stop around January 2026. Anything newer, including most recent facts about your company, reaches the model only at query time through live web search, the context you paste in, or files you upload.
Gemini's structural advantage here is obvious once you say it out loud: it is made by the company behind Google Search. Its answers can be grounded in live Google Search, and its Deep Research mode fans a question out across many sources and synthesizes them into a cited report. Tools like NotebookLM extend the same reach to your own documents. For anything that depends on current information, that reach is a real edge, and the citations come with clickable links you can check.
Claude's web search is newer and tends to be more conservative, pulling fewer sources and favoring authoritative or technical ones, and it is unusually strong when you paste a long document into its context window and ask it to reason over that instead of the open web. If your question is "summarize and pressure-test this 80-page contract," Claude's grounding on the material you hand it is a different and often better job than searching the web at all.
Now the part both share, and the one to take seriously. When web search is off, each model answers from frozen training memory, and either one can produce a confident, authentic-looking citation that does not exist. This is not lying. It is a known failure mode where the model recognizes the shape of a source and fills in plausible details, which is why both tools invent journal articles and URLs that were never real. We cover the mechanism in AI hallucinations. Turning on web search reduces it sharply but does not make it zero, so the citation a model hands you is a lead to verify, never a guarantee. Both sit on the same underlying machinery of how AI search works; they just feed it from different indexes.
Claude vs Gemini for Writing, Coding, and Research
Sorted by job, the picture gets clearer than any overall winner. Here is where each one tends to land, with the caveat that matters for each.
| Use case | Usually leans | Why | The caveat |
|---|---|---|---|
| Long-form writing and editing | Claude | More natural prose, less filler, holds a long document in working memory well | Leans agreeable; you have to ask it directly for hard critique |
| Coding | Contested, slight Claude lean | Strong agentic coding and Claude Code, plus a coding-benchmark edge | A benchmark lead is not an implementation lead; Gemini competes hard on cost and context |
| Live research and current info | Gemini | Live Google grounding and Deep Research pull more, fresher sources | More sources is not more accuracy; the summary can rest on weak ones |
| Generating images, video, and voice | Gemini | Native generation across image, video, and audio | Claude does not generate media at all; for created images or video, Gemini is the tool |
| Very long documents | Split | Both run near a 1M-token window today, with 3.5 Pro rumored to go higher; Claude tends to stay coherent across a long one | Advertised context is not the same as reliable recall, so test it on your own documents |
| Google Workspace tasks | Gemini | Built directly into Gmail, Docs, and Sheets | Native beats a connector; Claude reaches these through add-ons, not from inside |
On writing, Claude's edge is real but comes with a tell: it leans agreeable. Ask it to critique your draft and it will often soften the verdict, so you have to explicitly tell it to be harsh. Gemini's prose is strong and stylistically more neutral; some readers prefer that, others find Claude's voice less corporate, and it is a matter of taste more than a quality gap. Neither replaces an editor.
On coding, Claude currently leads the headline benchmark, SWE-bench Verified, though that score is self-reported and the lead has changed hands before. The real-world choice is closer and depends on your stack: Claude has the stronger reputation for long, multi-file agentic work, while plenty of developers get equal or better results from Gemini on their own code, and Gemini runs far cheaper at volume. Benchmark leadership and the build that actually compiles on your machine are different claims.
On research, Gemini's live grounding is a clear advantage for anything time-sensitive, but the same caution from our comparison of ChatGPT vs Perplexity applies: a research-style answer is only as good as the sources it grounded on. Read the links, do not trust the summary.
One nuance the tables flatten: both models read images, screenshots, and PDFs you hand them well, so on understanding multimodal input they are close. The gap is generation, where only Gemini makes new images, video, and audio.
Claude Code vs Gemini CLI: Coding in the Terminal
The most useful coding comparison right now is not the chat models, it is the terminal agents, and that is the matchup nobody covers. Both companies ship a command-line tool that turns the model into an agent that reads your codebase, plans, edits multiple files, runs commands, and checks its own work. They take different bets.
Claude Code is the more mature of the two on long, multi-step tasks. It holds intent across a complex job, recovers from its own errors reasonably well, and connects to external tools through the Model Context Protocol. Its main cost is exactly that: cost, plus the usage caps that bite hardest during heavy agentic sessions.
Gemini CLI is open source, and Google has paired it with an unusually generous free quota and a 1M-token context window. Running on Gemini's Flash-class models, such as Gemini 3.6 Flash, the current default and tuned for sustained agentic and coding work, it is fast and cheap enough to leave running, and it slots into Google's broader developer tooling. For large repositories where context size matters, or for anyone watching spend, it is a serious option rather than an also-ran.
The honest call: Claude Code still feels a step ahead on agentic coherence for hard, long tasks, while Gemini CLI wins on cost, openness, and raw context. Pick by your budget and which ecosystem you already live in, and re-test after any major release, because this is the fastest-moving corner of the whole comparison.
What the Benchmarks Actually Say (Read Them Skeptically)
Benchmarks are the most quoted and least understood part of any comparison. They are useful for spotting which models are roughly in the frontier tier and nearly useless for picking a daily driver. Here is the honest state of the major ones as of July 2026.
| Benchmark | What it measures | Reported leader (July 2026) | Read it with |
|---|---|---|---|
| SWE-bench Verified | Resolving real GitHub issues (coding) | Claude's frontier models lead: Opus 4.8 at 88.6% (the model these scores were run against, since succeeded by Opus 5) and Fable 5 at 95%, against 80.6% for Gemini 3.1 Pro, roughly an eight-point gap, wider than most comparisons imply | Scores are largely self-reported and swing with the test harness |
| GPQA Diamond | Graduate-level science questions (reasoning) | Contested; the two trade the lead | Scores sit near the ceiling, so tiny gaps look bigger than they are |
| Humanity's Last Exam | Hard expert reasoning, no tools | Both rank at the frontier; the lead has traded between them | A young, brutal benchmark; low scores with wide error bars |
| LMArena | Human head-to-head preference votes | Claude and Gemini both rank among the top models in text | This measures what people prefer, not what is correct |
| Long-context recall | Finding facts buried in a huge input | Gemini's larger window helps on the biggest inputs | Recall still degrades in the middle of long contexts for every model |
Four things keep these numbers from meaning what they look like. First, most headline coding scores are self-reported by the labs, and the same model can swing several points depending on the scaffolding around it. Second, the older general-knowledge tests are effectively saturated, with everyone scoring in the high 80s and 90s, so they no longer separate the top models. Third, the leads flip almost monthly as each lab ships, so any single number is a snapshot, not a standing. Fourth, LMArena rewards the answers people prefer, which tracks quality but also rewards confident, well-formatted responses that are not always right.
The practical takeaway is dull but true: by mid-2026 the frontier models from both labs are close enough that benchmark gaps rarely decide a real workflow. The benchmark that counts is your own work, run through both.
Pricing, Usage Limits, Privacy, and the Google Ecosystem
The specs people compare are rarely the things that decide it. Four practical factors matter more.
Price and limits. At the consumer level the two are close: Claude Pro and Google AI Pro both sit around $20 a month, with higher tiers (Claude Max and Google AI Ultra) running $100 to $200. Gemini has the cheaper entry point, an AI Plus tier around $5 (cut from $8 in June 2026), and generally looser usage caps. That last part is the one heavy users feel most: Claude's tighter limits are the friction they hit soonest, while Gemini lets you keep going, and Gemini's free tier is the more generous of the two. On the API, Gemini's price edge is real but narrower than the shorthand suggests: its Pro tier undercuts Claude's Opus per token ($2/$12 against $5/$25). But "Flash is cheaper than almost anything" no longer holds: Gemini 3.6 Flash runs $1.50/$7.50 per million tokens, while Claude's Haiku 4.5 is $1.00/$5.00, cheaper on both. Claude's Sonnet 5 even undercuts Gemini 3.1 Pro on output at its introductory $2/$10 (through August 31, 2026). At volume, which one is cheaper depends on the pair you compare, not the logo.
The Google ecosystem. This is Gemini's quiet trump card. It is built into Gmail, Docs, Sheets, and Android, so for the millions of people already living in Workspace, Gemini is the assistant that is simply there, in the document, with the context already loaded. Claude reaches those tools through add-ons, which is not the same as being native. If your work happens inside Google's products, that integration can outweigh any model-quality difference.
Privacy. As of July 2026 both makers train on consumer chats by default and let you opt out, while business, enterprise, and API tiers are excluded from training by default. Anthropic changed Claude's consumer default in 2025, so whatever you remember about Claude not training on your data may be out of date. Some people are wary of Gemini specifically because it is Google, the same company whose business runs on data and ads; that is fair to weigh, though the practical training controls are similar on both sides. If your work is sensitive, use a business tier or check the data settings on whichever one you run.
Drift. Both models change under you. New versions ship constantly, old ones retire, and people regularly report a model feeling worse after an update, sometimes real, sometimes perception. Re-test your own workflow after any major release rather than trusting last quarter's verdict.
Which One Should Your Brand Appear In?
If you publish or market anything, the question that pays is not which tool you use. It is which one names your brand when your customer asks. Both Claude and Gemini are answer engines now. People ask them which product to buy, which agency to hire, which tool is best, and the answer either includes you or it does not. In that moment the citation is the impression, and the ones you lose stay invisible unless you go looking.
This is not a fringe behavior, and the clearest measured case so far is Google's own search. A 2025 Pew Research Center study found that when an AI summary appeared in Google results, users clicked a traditional result link in just 8% of visits, against 15% when there was no summary, nearly halving the click-through. That study measures Google AI Overviews and U.S. Google users, not Claude or Gemini directly, but it captures the same shift: as more answers get consumed without a click, being inside the answer matters more than ranking below it.
Here the two engines split in a way that is specific to this matchup. Gemini draws on Google's own index, so your classic Google SEO and your Gemini visibility overlap heavily, which is convenient if you already rank and a problem if you do not. The overlap is not total, though: Google's AI surfaces use their own retrieval signals, so ranking first does not guarantee a citation. Claude pulls from its own newer web search, a more independent surface that leans toward authoritative sources. Showing up in one says little about the other, which turns into two concrete jobs. For Gemini and Google's AI Overviews, the work is mostly strong classic ranking, clean crawlable HTML, and structured data. For Claude, getting cited rewards plain, well-organized, authoritative prose over keyword-padded pages.
You cannot control which model a customer opens, and you cannot control the dice on any single answer. In our experience auditing brands across these engines, the most common and most fixable problem is simply not knowing the score: companies are absent from AI answers about their own category and have no idea, because they are still watching blue-link rankings. You cannot improve a number you are not measuring, which is the whole case for tracking your AI share of voice per engine rather than guessing.
How We Use Both, and Why the Loop Beats the Model
A note on where this comes from. We run an SEO agency, build a GEO tool, and do security research, and most of that work runs through Claude in Claude Code. But Gemini earns a real place in the stack: when we need something current off the live web, a fast pass over a giant document, or media we cannot make in Claude, Gemini is the right tool, and we reach for it without ceremony. So this is not a spec-sheet comparison. It is how we use both every day.
The thing we learned the hard way is that the model matters less than the loop around it. A model reviewing its own work is notoriously bad at catching its own mistakes. It rereads its error and confidently approves it, because the same blind spot that produced the mistake is doing the checking. The fix is not a smarter model. It is a second, adversarial pass, ideally from a different model family, because a different model fails in different places and sees what the first one cannot.
So we never ship a first draft. Whether it is an article, a line of production code, or a security finding, it goes through several harsh, independent reviews before it counts. This article is an example: one model wrote it, then independent reviewers and a separate cross-model pass tore into it and caught real problems the draft was blind to. We use these models against each other on purpose, which is the same reason geotoolbox measures AI visibility by sampling many times instead of trusting one check.
So, Claude or Gemini? How to Decide
Pick by task, not by leaderboard. Reach for Claude when you are writing, editing, or reasoning over long documents, and when you want a careful, low-fluff style. Reach for Gemini when you need current information off the live web, images or video, deep Google Workspace integration, or the broader Google ecosystem. Both have free tiers, so the cheapest way to settle the debate for your own work is to put the same real task through each and stop looking for a universal winner that does not exist.
For a business, the calculus is different, and it has nothing to do with which model is smarter. Your customers use both, so the question that actually moves revenue is not which one you prefer, but which one cites you when someone asks about your category, and how that compares to your competitors.
That is the gap geotoolbox closes. We track what Claude, Gemini, and the other engines actually say and cite about your brand, per engine and over time, so you can see where you show up, where a competitor owns the answer, and what to fix. You can start with a free AI readiness check to see whether these engines can even read your site, then watch your presence across them in the domain overview. The models will keep trading the lead. Whether they mention you is the part you can work on.
Frequently Asked Questions
Is Claude better than Gemini?
It depends on the task, and that is the honest answer rather than a dodge. As of July 2026, Claude tends to win on long-form writing, document reasoning, and careful, concise output, while Gemini wins on live web research, multimodal generation, very long context, and deep Google Workspace integration. Coding is close. For most people there is no single winner, which is why heavy users often use both and switch by task.
Is Gemini or Claude better for coding?
The two are close, with a slight edge to Claude on hard, multi-step agentic work, and a real cost-and-context edge to Gemini. Claude Code has the stronger reputation for holding a long task together, while Gemini CLI is open source, cheaper to run, and ships a 1M-token context window that helps on big repositories. Benchmark results move with each release, so the only test that settles it is your own codebase.
Does Gemini have a bigger context window than Claude?
Right now they are close, and the answer depends on the model. On paid plans Claude gives you 1M tokens when chatting with Opus 5 or Sonnet 5, and the same 1M through the API. Gemini's app gives 1M tokens to AI Pro and Ultra subscribers, 128K on AI Plus and 32K without a subscription. Gemini 3.5 Pro is rumored to target 2M, though Google has published no official spec — if true, that would pull Gemini ahead once it ships. A bigger window is not the same as better recall, though: every model gets less reliable at finding facts buried in the middle of a very long input, so window size is a ceiling, not a guarantee.
Is Claude or Gemini cheaper?
At the consumer level they are close, both around $20 a month for the main paid plan, with Gemini offering a cheaper entry tier around $5. At the API it depends on the pair: Gemini 3.1 Pro ($2/$12 per million tokens) undercuts Claude's Opus 5 ($5/$25), but Claude's Haiku 4.5 ($1/$5) undercuts Gemini's 3.6 Flash ($1.50/$7.50) on both input and output. Claude's tighter usage limits also cut heavy sessions off sooner. Which one bills less at volume depends on which models you actually run, not on the logo.
Which one hallucinates less, or cites sources better?
Gemini's live grounding in Google Search gives it more current sourcing with clickable links, while Claude tends to pull fewer sources, favoring authoritative ones, and is strong at grounding answers in a document you provide. With web search off, both answer from training memory and either can invent a confident, fake-but-plausible citation. The safe rule is the same for both: treat every cited source as a lead to verify, not proof.
Is Claude or Gemini better than ChatGPT?
No model is the single most powerful; at the frontier, Claude, Gemini, and ChatGPT trade the lead. ChatGPT is the broad generalist with the widest tool ecosystem and native image generation, Gemini owns live Google grounding and Workspace integration, and Claude leads on long-form writing and agentic coding. The gemini vs claude decision usually comes down to ecosystem and task; if you are weighing the wider field, our Claude vs ChatGPT, Gemini vs ChatGPT, Grok vs Gemini, and Grok vs Claude comparisons cover those pairings directly.
Does it matter which one my brand shows up in?
Yes, because your customers use both, and the two engines draw on different sources, so being mentioned in one does not mean being mentioned in the other. Gemini leans on Google's index, so it tracks your classic SEO; Claude uses its own web search and rewards authoritative, well-structured pages. As people get more answers without clicking, the practical step is to measure how often each engine cites you, per engine and over time, and fix the gaps rather than guess.
Sources
- Anthropic - Constitutional AI: Harmlessness from AI Feedback -
anthropic.com/research/constitutional-ai-harmlessness-from-ai-feedback - Anthropic - Claude models overview (current models, context windows, pricing) -
platform.claude.com/docs/en/about-claude/models/overview - Google DeepMind - Gemini models -
deepmind.google/models/gemini - Google - Gemini 3.5: frontier intelligence with action -
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5 - Google - Grounding with Google Search (Gemini API) -
ai.google.dev/gemini-api/docs/google-search - Google One - AI plans (Free, AI Plus, AI Pro, AI Ultra) -
one.google.com/about/google-ai-plans - Google - Gemini CLI (open-source terminal agent) -
github.com/google-gemini/gemini-cli - SWE-bench - software engineering benchmark -
swebench.com - LMArena - human-preference LLM leaderboard -
arena.ai/leaderboard - Pew Research Center - Google users are less likely to click links when an AI summary appears -
pewresearch.org/short-reads/2025/07/22/google-users-are-less-likely-to-click-on-links-when-an-ai-summary-appears-in-the-results